- Published
Konsep Dasar Kecerdasan Buatan (AI), Machine Learning, dan Deep Learning
- Published
- Gaudhiwaa Hendrasto
Dibalik teknologi canggih autonomous car pada mobil Tesla, ChatGPT, dan Bing Image Creator, kecerdasan buatan memegang peranan sentral dalam pengembangan produknya.
Kecerdasan buatan atau sering kali juga disebut sebagai Artificial Intelligence (AI) adalah kemampuan mesin dalam menyerupai atau mensimulasikan kecerdasan kognitif manusia, termasuk di antaranya meliputi kemampuan persepsi, penalaran, pembelajaran, interaksi, pemecahan masalah, hingga kreativitas (McKinsey, 2023).
Dalam satu dekade terakhir, terobosan AI semakin gencar dilakukan dan menjadi buah bibir masyarakat dunia. From Chatbot to Cyborg, merupakan istilah yang pantas dalam merepresentasikan potensi manfaat sekaligus malapetaka AI. Apa iya AI berbahaya buat manusia? Emang bener AI bisa gantiin pekerjaan manusia? Masa sih?! 🧐
Untuk memahami diskursus tersebut, kita perlu mengetahui tentang cara kerja dan ruang lingkup penerapannya. Dalam artikel ini, saya akan membantu Anda dalam mendalami pengetahuan tentang AI, dengan mengetahui: AI itu apa sih? Gimana sih cara kerjanya? Gimana sih cara buatnya? 🤔
Ambil posisi duduk yang nyaman—mau rebahan juga boleh 😉—karena kita akan membahas AI secara komprehensif! 🥂
Catatan penulis:
Jika kamu tertarik belajar AI dan masih tahap awal, saya sarankan untuk memahami beberapa pembelajaran inti berikut:
- Perbedaan AI, Machine Learning (ML), dan Deep Learning (DL).
- Tugas Machine Learning: Regresi, Klasifikasi, dan Clustering.
- Cara pembelajaran Machine Learning: Supervised, Unsupervised, dan Reinforcement Learning.
Materi lainnya seperti algoritma, evaluasi, tahapan pembuatan dsb. bisa dipelajari secara bertahap.
Daftar Isi
Ruang Lingkup


Gambar di atas merepresentasikan ruang lingkup dari AI, yang di dalamnya terdapat machine learning dan deep learning. Seringkali apa yang kita sebut AI sebenarnya—secara spesifik—merupakan machine learning atau deep learning. Ketiganya merupakan satu kesatuan, tetapi sebenarnya berbeda. Skema di bawah ini menjelaskan mengenai perbedaan di antaranya:
| Kriteria | Definisi | Instruksi | Algoritma | Kegunaan |
|---|---|---|---|---|
| Artificial Intelligence (AI) | Cabang ilmu komputer yang bertujuan memberikan kecerdasan kepada mesin agar dapat melakukan tugas-tugas yang membutuhkan keahlian manusia. | Memerlukan instruksi eksplisit untuk melakukan tugas tertentu. | Fuzzy, Decision Tree, Genetic Algorithm. | Bot game, robotika. |
| Machine Learning (ML) | Sub-disiplin AI yang menggunakan algoritma untuk memungkinkan mesin belajar dari data dan tanpa perlu diprogram secara eksplisit. | Mempelajari dari data tanpa instruksi eksplisit. | Linear Regression, Logistic Regression, Polynomial Regression, Random Forest, Support Vector Machines (SVM), K-Nearest Neighbors (KNN). | Prediksi, klasifikasi, clustering, rekomendasi. |
| Deep Learning (DL) | Sub-disiplin ML yang menggunakan arsitektur jaringan saraf tiruan (ANN) untuk memodelkan dan memahami representasi data yang kompleks. | Menggunakan pembelajaran mendalam dan perangkat keras khusus untuk mengekstrak fitur yang rumit dari data. | Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM), Generative Adversarial Networks (GAN). | Pengenalan gambar, pengenalan suara, terjemahan mesin, pemrosesan bahasa alami (NLP). |
Definisi: Cabang ilmu komputer yang bertujuan memberikan kecerdasan kepada mesin agar dapat melakukan tugas-tugas yang membutuhkan keahlian manusia.
Instruksi: Memerlukan instruksi eksplisit untuk melakukan tugas tertentu.
Algoritma: Fuzzy, Decision Tree, Genetic Algorithm.
Kegunaan: Bot game, robotika.
Machine Learning (ML):Definisi: Sub-disiplin AI yang menggunakan algoritma untuk memungkinkan mesin belajar dari data dan tanpa perlu diprogram secara eksplisit.
Instruksi: Mempelajari dari data tanpa instruksi eksplisit.
Algoritma: Linear Regression, Logistic Regression, Polynomial Regression, Random Forest, Support Vector Machines (SVM), K-Nearest Neighbors (KNN).
Kegunaan: Prediksi, klasifikasi, clustering, rekomendasi.
Deep Learning (DL):Definisi: Sub-disiplin ML yang menggunakan arsitektur jaringan saraf tiruan (ANN) untuk memodelkan dan memahami representasi data yang kompleks.
Instruksi: Menggunakan pembelajaran mendalam dan perangkat keras khusus untuk mengekstrak fitur yang rumit dari data.
Algoritma: Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM), Generative Adversarial Networks (GAN).
Kegunaan: Pengenalan gambar, pengenalan suara, terjemahan mesin, pemrosesan bahasa alami (NLP).
Dengan kata lain bisa kita katakan bahwa: terdapat AI yang bukan machine learning, dan terdapat machine learning yang bukan deep learning.
Dengan sedikit memahami perbedaan AI, machine learning, dan deep learning kita sudah cukup tahu mengenai ruang lingkup AI. Saatnya memasuki bagian yang agak teknis! 🥂
A. Artificial Intelligence
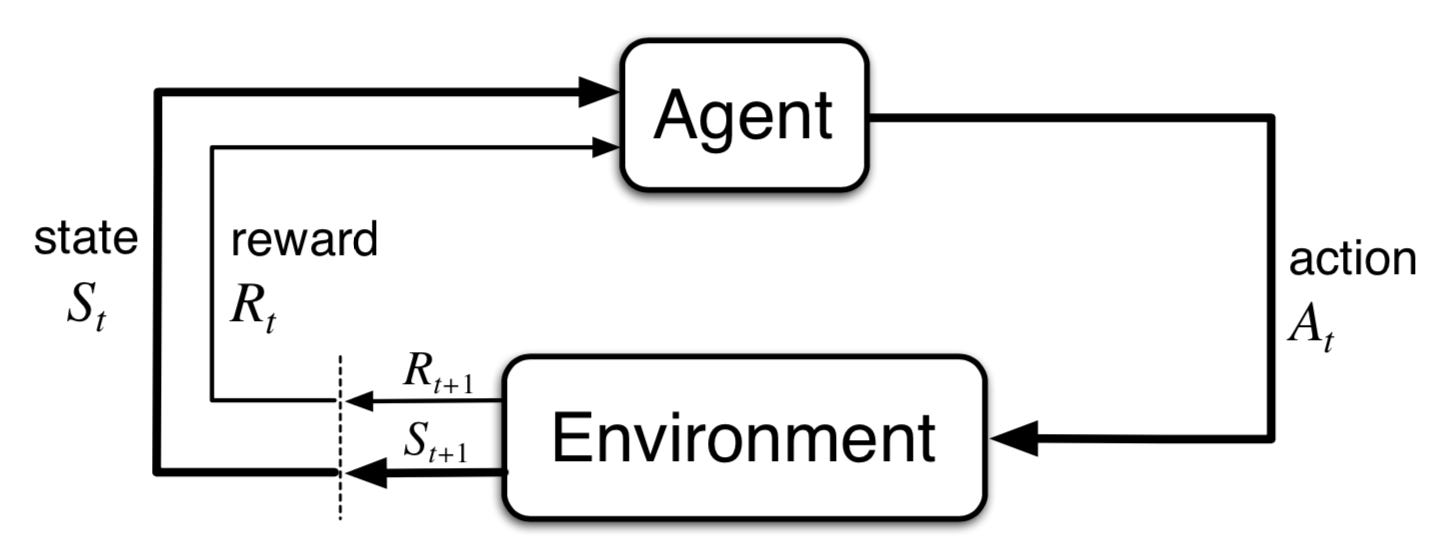
Di atas ini merupakan paradigma bagaimana cara AI bekerja, dengan penjelasan sebagai berikut:
| Konsep | Deskripsi |
|---|---|
| Agent | Objek AI |
| Environment | Lingkungan dari agent |
| Action | Aksi yang dilakukan terhadap environment |
| State | Kondisi atau situasi saat ini |
| Reward | Umpan balik positif terhadap action yang dilakukan oleh agent |
Dengan mengetahui konsep di atas, kita dapat lebih mudah dalam membuat program AI. Cara kerjanya adalah:
Agent akan melakukan action dengan reward terbesar berdasarkan state (kondisi saat ini).
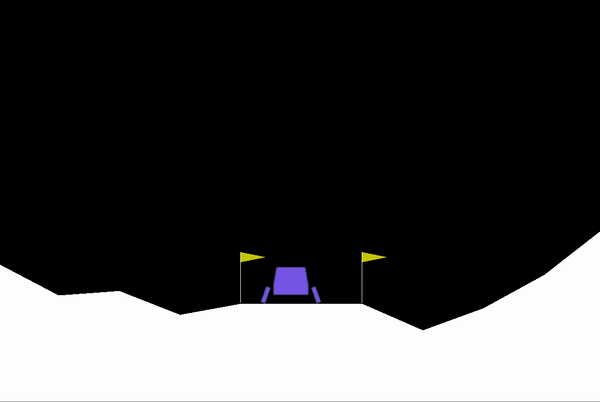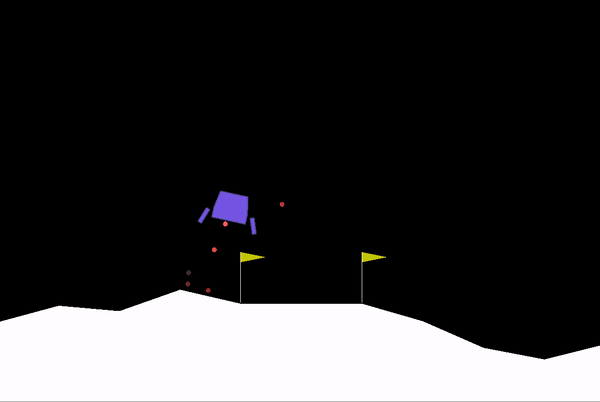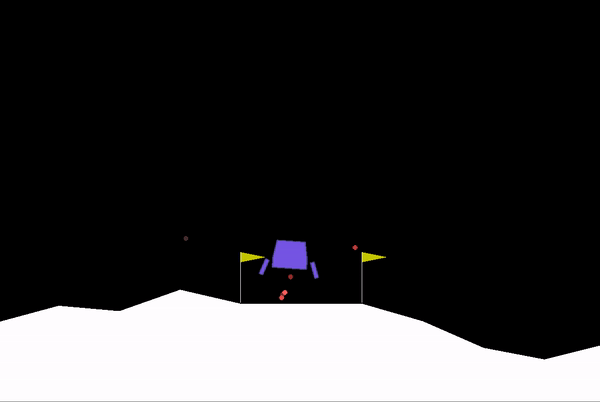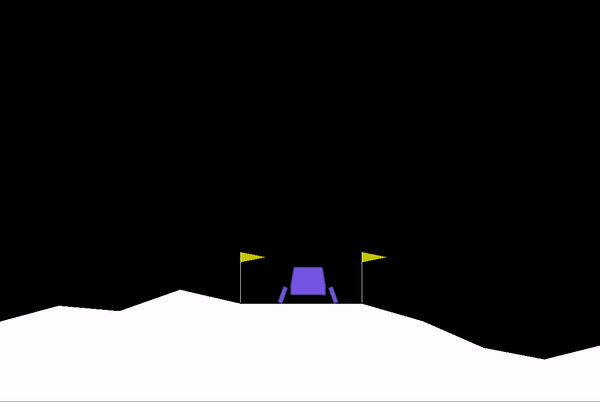
Supaya dapat dipahami dengan baik, saya akan menggunakan aplikasi nyatanya pada bot catur. Tujuan utama bot catur ini adalah berusaha semaksimal mungkin untuk dapat memenangkan permainan dengan mengancam raja (check mate).
Konsep bot catur ini dideskripsikan sebagai berikut:
| Konsep | Deskripsi |
|---|---|
| Agent | Bidak catur putih |
| Environment | Papan catur (8x8), posisi bidak putih dan hitam |
| Action | Memindahkan salah satu bidak catur putih (pion, benteng, kuda, ratu dll.) |
| State | Posisi bidak putih dan hitam |
| Reward | Total poin berupa: keuntungan material bidak + kualitas posisi + ancaman terhadap raja + keamanan raja |
Jika diimplementasikan dalam bentuk salah satu algoritma, yaitu decision tree, maka bentuknya seperti gambar di bawah ini. Pohon-pohon tersebut merepresentasikan action yang mungkin dilakukan berdasarkan state saat ini. Pohon yang berwarna putih mengartikan bidak putih melakukan action, sedangkan pohon yang berwarna hitam mengartikan bidak hitam melakukan action. Di ujung paling akhir pohon tersebut terdapat reward berupa angka, yang akan menjadi pertimbangan action yang akan dipilih. Action dengan reward paling besar akan dipilih oleh agent.
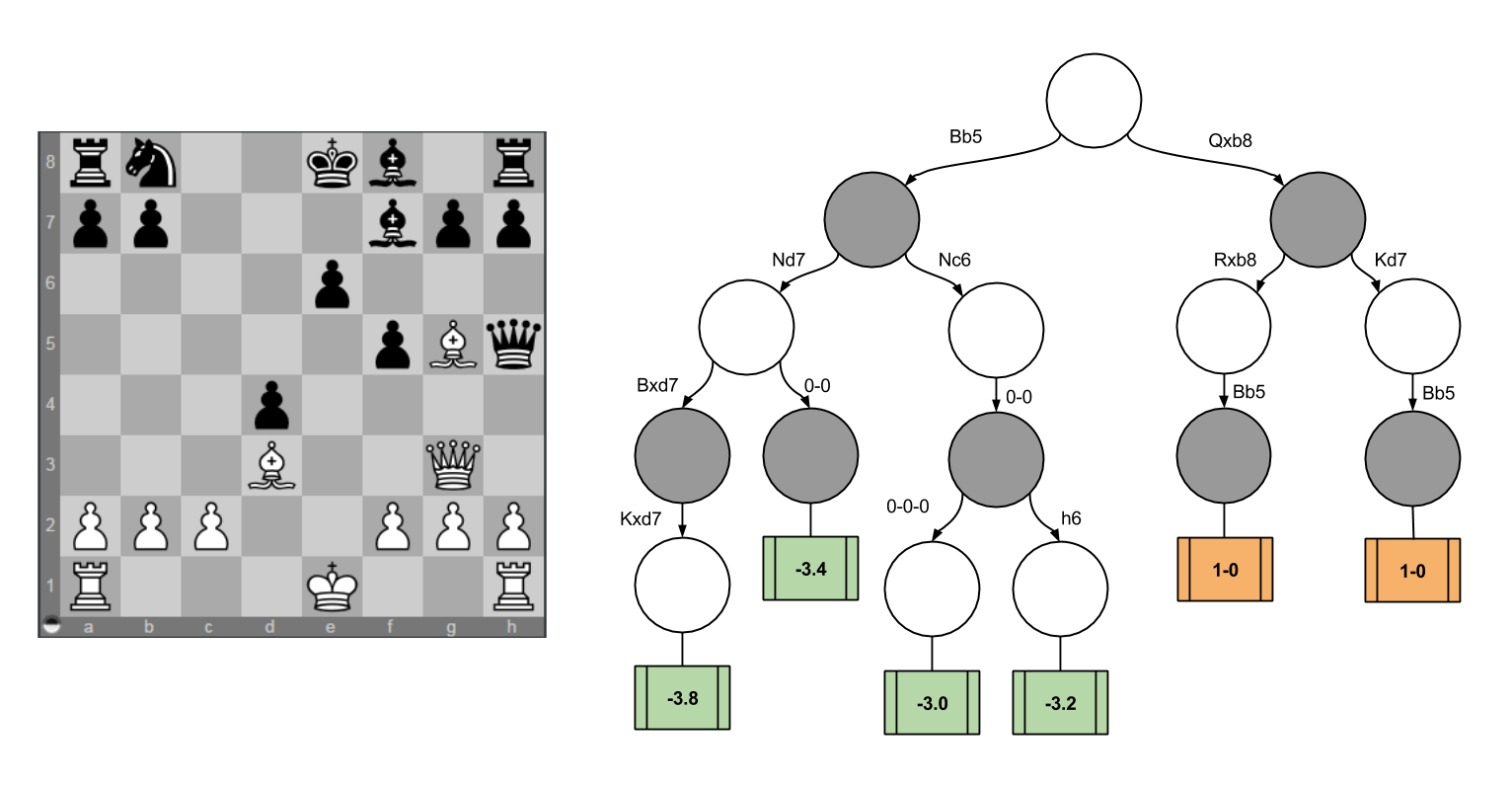
Sekilas ini mirip dengan konsep IF-ELSE bukan? Ya, pada AI (yang bukan ML) kode pemrograman masih perlu ditulis secara eksplisit, karena komputer belum bisa belajar secara otomatis dari data yang disediakan.
Tambahan: Jika kita berpikir lebih jauh, kemungkinan dari action yang bisa dilakukan pada bot catur ini bisa tak terhingga jumlahnya. Oleh karena itu, seringkali, dalam kasus ini, pembuatnya menggunakan parameter depth (kedalaman decision tree) untuk mengantisipasi keputusan yang terlalu dalam dan tak kunjung selesai. Itulah mengapa jika Anda bermain catur dengan bot dengan tingkat kesulitan hard, bot akan lebih lama dalam menentukan pilihan terbaik.
B. Machine Learning
Machine learning didefinisikan pada tahun 1950 oleh pionir AI, Arthur Samuel, sebagai bidang studi yang memberikan kemampuan komputer untuk belajar tanpa secara eksplisit diprogram. Dalam konteks ini, berbeda dengan AI, komputer dapat belajar melalui data yang disediakan menggunakan sebuah algoritma.
Tugas Machine Learning
Secara umum, tugas machine learning terbagi menjadi tiga, yaitu: regresi, klasifikasi, dan clustering. Konsep ini penting untuk diketahui sebagai representasi data dan tugas dari utama dari machine learning.
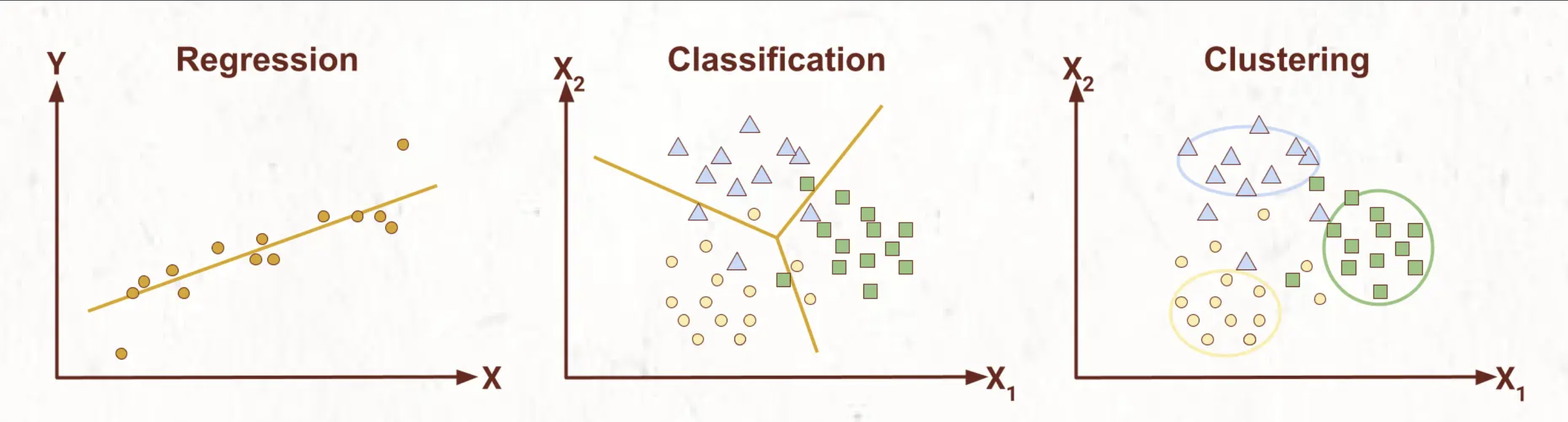
Apa sih beda antara ketiganya? Simak ulasan berikut:
| Konsep | Definisi | Algoritma | Kegunaan | Evaluasi |
|---|---|---|---|---|
| Regresi | Menemukan hubungan atau pola antara variabel independen dan variabel dependen untuk membuat prediksi nilai kontinu. | Linear Regression, Ridge Regression, Lasso Regression, Polynomial Regression | Prediksi harga rumah berdasarkan fitur-fitur seperti jumlah kamar dan luas tanah. | Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE), R-squared (R2). |
| Klasifikasi | Menyortir atau mengelompokkan data ke dalam kategori atau kelas tertentu berdasarkan fitur-fitur tertentu. | Decision Trees, Random Forest, Support Vector Machines (SVM), K-Nearest Neighbors (KNN) | Identifikasi jenis kelamin berdasarkan fitur-fitur seperti tinggi dan berat. | Akurasi, presisi, recall, F1-Score, Area Under the ROC Curve (AUC-ROC). |
| Clustering | Mengelompokkan data ke dalam kelompok atau klaster yang memiliki kemiripan internal. | K-Means Clustering, Hierarchical Clustering (Agglomerative), DBSCAN, Gaussian Mixture Model (GMM) | Segmentasi pelanggan berdasarkan perilaku pembelian. | Silhouette Score, Davies-Bouldin Index, Calinski-Harabasz Index, Adjusted Rand Index (ARI), Normalized Mutual Information (NMI). |
Definisi: Menemukan hubungan atau pola antara variabel independen dan variabel dependen untuk membuat prediksi nilai kontinu.
Algoritma: Linear Regression, Ridge Regression, Lasso Regression, Polynomial Regression
Kegunaan: Prediksi harga rumah berdasarkan fitur-fitur seperti jumlah kamar dan luas tanah.
Evaluasi: Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE), R-squared (R2).
2. KlasifikasiDefinisi: Menyortir atau mengelompokkan data ke dalam kategori atau kelas tertentu berdasarkan fitur-fitur tertentu.
Algoritma: Decision Trees, Random Forest, Support Vector Machines (SVM), K-Nearest Neighbors (KNN)
Kegunaan: Identifikasi jenis kelamin berdasarkan fitur-fitur seperti tinggi dan berat.
Evaluasi: Akurasi, presisi, recall, F1-Score, Area Under the ROC Curve (AUC-ROC).
3. ClusteringDefinisi: Mengelompokkan data ke dalam kelompok atau klaster yang memiliki kemiripan internal.
Algoritma: K-Means Clustering, Hierarchical Clustering (Agglomerative), DBSCAN, Gaussian Mixture Model (GMM)
Kegunaan: Segmentasi pelanggan berdasarkan perilaku pembelian.
Evaluasi: Silhouette Score, Davies-Bouldin Index, Calinski-Harabasz Index, Adjusted Rand Index (ARI), Normalized Mutual Information (NMI).
Macam-macam Cara Pembelajarannya
Berdasarkan cara pembelajarannya, machine learning dapat dikategorikan menjadi tiga, yaitu: supervised learning, unsupervised learning, dan reinforcement Learning.
1. Supervised Learning (Dataset berlabel)
Dataset yang memiliki label—atau juga sering disebut sebagai target—merupakan kategori dari supervised learning.
| Luas Tanah (meter persegi) | Jumlah Kamar Tidur | Jarak ke Pusat Kota (km) | Harga Rumah (Juta Rupiah) |
|---|---|---|---|
| 150 | 3 | 5 | 700 |
| 200 | 4 | 10 | 900 |
| 120 | 2 | 3 | 600 |
| 250 | 5 | 15 | 1200 |
| 180 | 3 | 8 | 800 |
Di atas ini merupakan contoh dari dataset supervised learning. Harga Rumah (Juta Rupiah) bisa kita katakan sebagai label. Dengan menggunakan dataset ini, model machine learning bisa belajar dan memprediksi Harga Rumah (Juta Rupiah) berdasarkan Luas Tanah (meter persegi), Jumlah Kamar Tidur, dan Jarak ke Pusat Kota (km). Model dapat mempelajari pola dari input dan output data dengan menggunakan algoritma tertentu.

Penerapan supervised learning juga bisa kita lihat pada: deteksi email spam, face recognition, prediksi harga saham, image recognition, dan pada kasus-kasus dataset klasifikasi atau regresi lainnya.
2. Unsupervised Learning (Dataset tak berlabel)
Pembelajaran machine learning menggunakan dataset yang tidak memiliki label, merupakan kategori dari unsupervised learning.
| Id | Pembelian Produk A (Ribu Rupiah) | Pembelian Produk B (Ribu Rupiah) | Pembelian Produk C (Ribu Rupiah) |
|---|---|---|---|
| 1 | 50 | 30 | 20 |
| 2 | 20 | 10 | 30 |
| 3 | 40 | 25 | 15 |
| 4 | 30 | 20 | 10 |
| 5 | 10 | 15 | 25 |
Di atas ini merupakan contoh dari dataset unsupervised learning, di mana dataset tersebut memiliki kolom Nama Pelanggan, Pembelian Produk A (Ribu Rupiah), Pembelian Produk B (Ribu Rupiah), dan Pembelian Produk C (Ribu Rupiah). Kita lihat bahwa tidak terdapat—secara eksplisit—target yang kita inginkan dari pemodelan machine learning. Bentuk data seperti ini dapat digunakan untuk melakukan segmentasi (clustering) pelanggan berdasarkan pola pembelian mereka. Segmentasi ini berguna bagi perusahaan untuk menawarkan produknya kepada customer yang memiliki perbedaan karakteristik.

Penerapan unsupervised learning lainnya bisa kita lihat pada: rekomendasi produk (berdasarkan riwayat pembelian dan penelusuran), pengelompokan dokumen bedasarkan topik, deteksi anomali keamanan jaringan (mengidentifikasi perilaku jaringan), dan, bentuk dataset lainnya yang tidak memiliki label.
3. Reinforcement Learning
Reinforcement learning ialah pendekatan pelatihan machine learning yang menggunakan sistem pemberian penghargaan untuk perilaku yang diinginkan dan hukuman untuk perilaku yang tidak diinginkan (Hashemi-Pour, 2023). Prinsip kerjanya sama dengan AI bot catur yang telah diterangkan di atas. Bedanya reinforcement learning dapat belajar melalui pengalaman atau data tanpa secara eksplisit diprogram.
Tahapan Pembuatan Machine Learning

Di bawah ini merupakan alur tentang bagaimana model proses machine learning—secara umum—bisa diciptakan. Berikut ini adalah tahapan-tahapannya:
- Dataset yang akan digunakan akan melalui tahap preprocessing, yaitu tahap membersihkan, mengubah, dan mengorganisir data mentah. Tujuan dari preprocessing adalah meningkatkan kualitas data dan membuatnya lebih cocok untuk diproses oleh algoritma machine learning ataupun untuk analisis data.
- Selanjutnya dilakukan Exploratory Data Analysis (EDA), yaitu proses merangkum karakteristik utama dari data, yang pada umumnya menggunakan metode visualisasi. Tujuan utama dari EDA adalah untuk memahami struktur dan pola dalam data, mengidentifikasi hubungan antar variabel, dan menemukan wawasan dari dataset. Langkah-langkah dalam EDA mencakup pembuatan grafik, ringkasan statistik, analisis distribusi, dan eksplorasi korelasi antar variabel.
- Setelah data dianalisis, data akan melalui proses feature engineering. Feature engineering adalah proses dimana perlu dibuat atau mengubah fitur-fitur pada dataset agar algoritma machine learning dapat bekerja lebih efektif. Beberapa teknik feature engineering melibatkan: pemilihan fitur (feature selection), penanganan missing values, pengaturan skala (scaling) dll.
- Dataset yang telah melalui tahap preprocessing dan feature engineering akan dilakukan pembagian dataset, yaitu dataset training dan dataset testing. Seringkali pembagian ini dilakukan dengan rasio dataset training sebesar 80% dan dataset testing sebesar 20%. Dataset training akan digunakan sebagai data yang digunakan untuk pelatihan model machine learning, sedangkan dataset testing akan digunakan sebagai uji evaluasi terhadap performa model.
- Data training yang telah disiapkan selanjutnya akan masuk ke dalam proses training model. Training model adalah proses di mana model machine learning belajar dari dataset untuk dapat membuat prediksi. Proses pelatihan model melibatkan penggunaan algoritma dan penyetelan hyperparameter.
- Jika model telah dibuat, kita perlu menguji apakah performa dari model yang telah dibuat memiliki performa baik atau buruk. Oleh karena itu, pada kasus supervised learning, data testing (yang memiliki label kebenaran) berperan sebagai input dari pengujian model. Selanjutnya evaluasi—seringkali—dilakukan dengan menggunakan akurasi (datasest klasifikasi) atau Mean Absolute Error (datasest regresi), yaitu membandingkan label yang benar pada data testing dan prediksi yang dihasilkan oleh model. Jika pada kasus unsupervised learning, maka evaluasi—seringkali—menggunakan silhouette score, yaitu mengukur seberapa mirip suatu nilai dengan klusternya sendiri (kohesi) dibandingkan dengan kluster lainnya (separasi).
- Selanjutnya jika pengujian menghasilkan performa yang baik, maka model siap digunakan. Cara menggunakannya adalah kita hanya perlu memasukan input yang dibutuhkan dan model akan mengeluarkan output. Namun, jika pengujian menghasilkan performa yang buruk, kita perlu mengevaluasi: algoritma model yang digunakan, hyperparameter, atau bahkan preprocessing dan feature engineering yang telah dilakukan.
C. Deep Learning
Mengutip artikel dari situs Amazon, algoritma deep learning adalah algoritma yang mengadopsi struktur jaringan neural yang meniru fungsi otak manusia. Otak manusia terdiri dari jutaan neuron yang saling terkoneksi yang berfungsi dalam memahami dan mengolah informasi. Sejalan dengan itu, jaringan neural deep learning, terdiri dari sejumlah lapisan neuron buatan yang bekerja bersama di dalam sistem komputer. Yang membedakan deep learning dan machine learning adalah arsitektur pada algoritmanya.
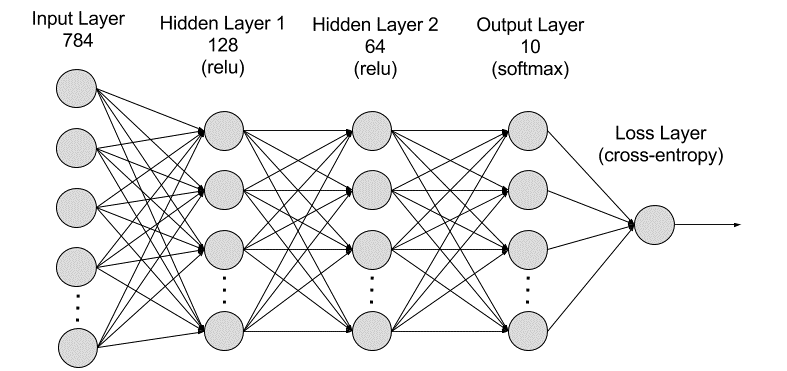
Berikut adalah komponen-komponen utama dalam jaringan deep learning:
Input Layer Jaringan neural buatan terdiri dari simpul-simpul yang berfungsi sebagai input data ke dalamnya.
Hidden Layer (relu): Lapisan input memproses dan meneruskan data ke lapisan lebih dalam di jaringan neural. Jaringan deep learning dapat memiliki ratusan hidden layer yang berfungsi untuk menganalisis masalah dari berbagai perspektif. Dalam konteks klasifikasi gambar bunga, hidden layer dapat membandingkan berbagai fitur seperti bentuk kelopak, warna, struktur tangkai, dan pola daun. Masing-masing lapisan berupaya mengidentifikasi pola khusus, seperti apakah bunga tersebut termasuk dalam kelompok tertentu berdasarkan karakteristik tertentu, seperti kelopak yang unik atau warna yang mencolok.
Output Layer (softmax): Lapisan output terdiri dari simpul-simpul yang menghasilkan data output. Model deep learning klasifikasi bunga yang menghasilkan output "mawar". "melati", dan "anggrek", memiliki tiga output layer. Sementara itu, model yang memberikan jawaban lebih kompleks memiliki lebih banyak simpul untuk mencakup variasi jawaban.
Di bawah ini merupakan visualisasi arsitektur model deep learning dalam mengklasifikasikan objek gambar menjadi angka.
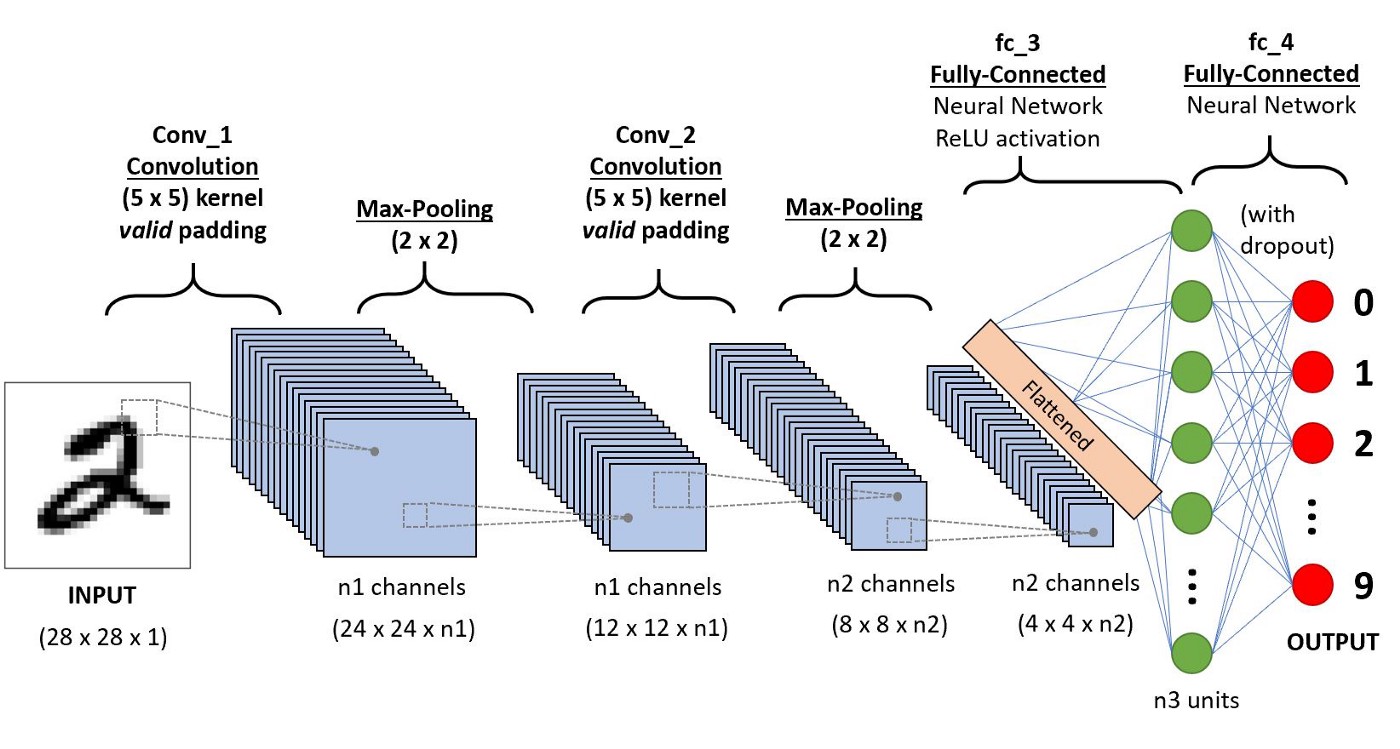
Contoh aplikasi deep learning lainnya dapat kita lihat pada: pemrosesan bahasa alami (NLP), pengenalan suara, autonomous car, prediksi harga saham, dan chatbot.
Sungguh menarik bukan belajar tentang AI? 😁
Yep, konsep-konsep ini memang agak cukup sulit dipahami bagi kamu yang baru belajar. But it's ok, learning takes time!⌛😉
Referensi: