- Published
Detection of Inconsistencies in the Laws of the Republic of Indonesia
- Published
- Surya Abdillah, Davian Benito, and Gaudhiwaa Hendrasto
The addition and modification of legal regulations always occur over time and can lead to disharmony, causing confusion in society when choosing a basis for action. On the other hand, the development of Artificial Intelligence, including Natural Language Processing, can be an approach to solving this issue and is expected to improve the efficiency and effectiveness of inconsistency checks.
Data consisting of 110 documents underwent information extraction, including articles and clauses. The extraction results then underwent data preprocessing, including case folding, link removal, spell checking, stemming, and stopword removal. The cleaned data underwent topic modeling using BERTopic and cosine similarity with a threshold value of 0.75. Pairs of clauses in the same cluster that exceeded the threshold were then subjected to inconsistency detection using the mDeBERTa model. ChatGPT was utilized to obtain harmonious and disharmonious pair data for training purposes.
Based on the performance testing, the best results were achieved with an accuracy of 93.07%, precision of 99.43%, recall of 86.57%, and an F1 score of 92.55% for the mDeBERTa model with a learning rate of 2e-5 and a batch size of 8, including the addition of legal regulation data.
Keywords: inconsistency detection, legal regulations, BERTopic, mDeBERTa, cosine similarity
Table of Content
- Background
- Problem Formulation
- Objectives
- Benefits
- Methodology
- Dataset
- Data Processing
- Data Extraction
- Data Preprocessing
- Topic Modeling
- Cosine Similarity
- Model Formation
- Pretrained Model
- Fine-tune First Model
- Generate New Data with ChatGPT
- Fine-tune Second Model
- Model Testing
- Discussion
- Results of Cosine Similarity Usage Scenario
- Results of Dataset Variation Scenario
- Results of Hyperparameter Tuning Scenario
- Prediction Results on All Documents
- Explanation of Prediction Results
- Conclusion
- Recommendations
- References
Background
According to Article 1 paragraph (3) of the 1945 Constitution, Indonesia is a legal state. This implies that all actions undertaken by society must be based on applicable law. Legal regulations, as one of the written legal norms, are one of the foundations of law referred to. In its development, these regulations are continually increasing, with numerous amendments. As of August 18, 2022, Indonesia has 42,161 regulations, excluding those issued directly by regional heads (Bayu, 2022).
However, with the passage of time and the increase in applicable regulations, problems arise in maintaining harmony among these regulations. Disharmony or inconsistency in legal regulations can be caused by differences in time and the institution forming the regulations, the turnover of officials forming the regulations, and the lack of coordination in the formation process. This inconsistency can lead to various serious issues in governance, such as differences in the interpretation of regulations, legal uncertainty, inefficient and ineffective regulation implementation, and legal dysfunction (Mahendra, 2010). One form of inconsistency among clauses is when one clause contradicts another.
Previous research by Wasis Susetio examined disharmony in land-related regulations. One highlighted point of disharmony was the status of forests, where it was mentioned as "forests located on land not burdened with land rights," while in the Agrarian Law, land not burdened with land rights is considered state land (Susetio, 2013). Correcting such disharmony becomes challenging because each sector is based on its specific sectoral legal regulations and holds equal status. Hence, addressing inconsistency needs to be done from the early stages of regulation formation to avoid difficulties.
Current solutions to address regulatory inconsistencies involve judicial reviews of the 1945 Constitution by the Constitutional Court or testing regulations under the Constitution by the Supreme Court (Wahyuni, 2023). However, this verification process is still done manually. This manual process results in inefficiency and ineffectiveness due to a higher probability of human error and a long duration for each issuance of new legal regulations. For instance, the amendment of Law Number 13 of 2003 concerning Manpower, filed by the PLN Workers Union, took nearly 10 months (from the first hearing to the decision, February 22 to December 13, 2017) (TV, 2022).
Therefore, digitization plays a crucial role in improving the existing system. Artificial Intelligence (AI), as one of the approaches used in digitization, has been widely implemented and proven effective in solving existing problems. The application of AI in problem-solving allows for effective and efficient resolution due to the automation processes carried out by computers and with a high level of accuracy. Based on this foundation, this research proposes the application of AI to address the issue of inconsistency in national legal regulations.
One form of AI application is the use of unsupervised learning on inconsistent sentences. The K-Means method has been employed to predict contradictions. The testing results show that the K-Means method performs well in detecting datasets containing redundant or inconsistent sentences overall. However, its performance significantly declines when applied to data that is not entirely redundant or consistent. Therefore, additional handling is required to address such data characteristics (Florence Sedes, 2018).
Supervised learning approaches, SVM, and KNN, have also been employed in predicting inconsistencies in security artifacts. Research by Xuni Huang showed an increase in model accuracy when using similarity features and word vectors. Moreover, the study used similarity value selection as part of the prediction for inconsistent labels (X, 2021).
Furthermore, previous research has compiled a dataset of contradictory sentences and developed a semantic-based prediction model. The model encountered difficulties in handling reasoning, comparative, and superlative cases involving numerical aspects (Fahrurrozi Rahman, 2021). Nevertheless, creating a similar model remains relevant to legal regulations since language models in regulations typically spell out numerical values.
Other studies indicate that the choice of the dataset in the model training process can significantly influence model performance (Laban, 2022). Thus, a dataset that aligns with the intended task is needed to enhance model performance. Data augmentation for training data also positively affects model performance (Nafide Sadat Moosavi, 2022). The use of the IndoNLI dataset is one approach to adapting the model, utilizing the Indonesian language. However, the language in regulations has standardized characteristics that differ from general language styles. Therefore, data augmentation of inconsistent and consistent sentences from legal regulations is needed to obtain the best-performing model.
Based on the above description, a system is proposed to detect inconsistency in legal regulations by applying topic modeling (BERTopic), cosine similarity thresholding, and mDeBERTa with the addition of augmented data for both consistent and inconsistent regulation sentences. Several testing scenarios are conducted to obtain the best-performing model.
Problem Formulation
The research addresses the following problems:
- How to prepare legal regulation data for topic modeling and inconsistency detection among clause pairs?
- How to perform topic modeling on legal regulation data?
- How to detect inconsistency among clause pairs?
- How to evaluate the inconsistency detection model?
Objectives
The objective of this research is to develop the application of AI in detecting inconsistency among clauses in national legal regulations. The AI model created is an NLP model capable of analyzing semantic relations among clauses to determine if there is inconsistency in the clause pairs.
Benefits
This research is expected to benefit various stakeholders, including:
- Supreme Court and Constitutional Court
- Gain considerations regarding regulations subject to judicial review and legal regulation testing.
- Legal regulation drafting institutions
- Ensure the production of high-quality national legal regulations by ensuring clause pairs are consistent with each other, both within the same document and across different documents.
- Create a more efficient system by reducing the need for amendments to existing legal regulations.
- Society
- Access justice in the legal process due to consistent and clear legal regulations, avoiding gaps that could lead to injustice.
- Clarity on the legal basis for every action.
- Judicial decisions
- Legal proceedings can proceed fairly without causing confusion, promoting consistent interpretations and the absence of contradictory regulations related to the case being tried.
- Legal proceedings can run smoothly and efficiently due to consistent and clear legal regulations.
Methodology
To achieve the aforementioned objectives, a research process flow is devised as shown in the image below.
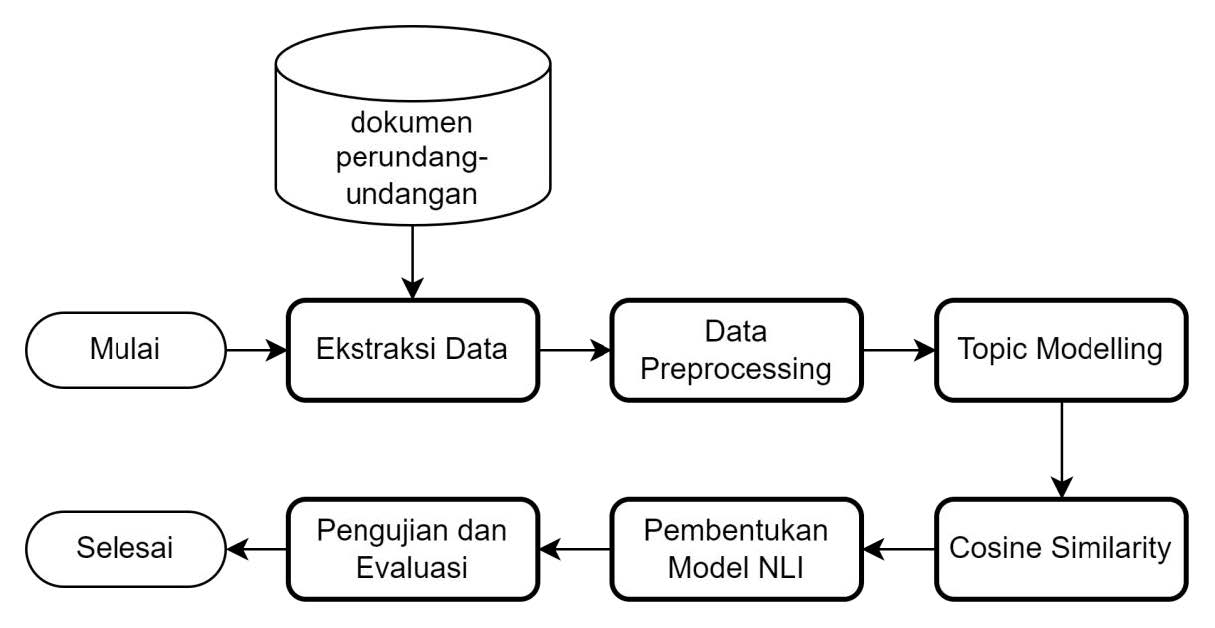
Dataset
The data used in this research consists of 110 documents (pdf and docx) of national legal regulations related to investments with various types, years, and levels. There are three principles in resolving conflicts among legal regulations: lex superior derogat legi inferiori (higher-level regulations override lower-level ones), lex specialis derogat legi generali (more specific regulations override more general ones), and lex posterior derogat legi priori (newer regulations override older ones) (Budianto, 2022). Based on Article 7 paragraph (1) of Law Number 12 of 2011 concerning the Formation of Laws and Regulations, the levels of regulations in this dataset are as follows:
- Law
- Government Regulation in Lieu of Law
- Government Regulation
- Presidential Regulation and Decree
- Ministerial Regulation and Decree
The dataset is available at: Google Drive
Data Processing
The existing document data undergoes processing, including feature extraction, data preprocessing, topic modeling, cosine similarity, and inconsistency detection in clause pairs.
Data Extraction
The dataset of legal regulation documents is then extracted to obtain information on types, numbers, years, subjects, article numbers, paragraph numbers, and clause text from each document. This extraction is done using a program capable of parsing documents based on sentence structure patterns in the document. The dataset consists of two types: dictum and article. The pseudocode below represents the document parsing algorithm for articles.
FUNCTION parse_document_article(document_path)
OPEN document_path
READ text from the file
CONVERT text to lowercase
INITIALIZE data dictionary with keys: 'article', 'paragraph', 'text'
INITIALIZE df DataFrame with data dictionary
INITIALIZE article_text_list as an empty list
SPLIT text into article_texts using article_pattern
FOR each article in article_texts starting from the second element
IF 'sufficiently clear.' is in article
BREAK from the loop
ENDIF
APPEND article to article_text_list
SPLIT article into paragraph_texts using paragraph_pattern
FOR each paragraph in paragraph_texts
ADD a new row to the DataFrame df with corresponding article number, paragraph number, and the stripped paragraph as the text
ENDFOR
ENDFOR
RETURN df, article_text_list, the document name from the path, and whether the length of article_text_list is greater than 2
ENDFUNCTION
The extracted results are then inserted into a data frame with feature columns consisting of document name, page count, regulation type, number, year, article number, paragraph number, subject, and article text. An example data frame from the extraction results can be seen in the images below.




Data Preprocessing
After obtaining sentences for each document, a text preprocessing stage is performed, which includes:
- Lower-Case
Convert all text data to lowercase to ensure uniformity and consistency in text capitalization. This is done to reduce the dimensionality of vocabulary features.
The subsection of correspondence has the task of handling general affairs, preparing correspondence, duplication, sealing, and archiving.
- Remove Links
Legal documents may sometimes contain links that are accidentally extracted with the sentences. These links are not part of the sentences and are irrelevant to the problem, so they need to be removed from the data.
The subsection of correspondence has the task of handling general affairs, preparing written correspondence, duplicating, sealing, and archiving.
- Spell Checker
Perform spell checking on extracted sentences, as there may be misspelled words. This step ensures that all words in the sentences are correctly spelled, contributing to the model's accuracy.
The subsection of correspondence has the task of handling general affairs, preparing written correspondence, duplicating, sealing, and archiving.
- Stemming
Convert all words to their base form to reduce morphological variations. Often, the base meaning of words in a sentence can represent the entire sentence.
The subsection of letters has the task of handling general affairs, preparing letters, duplicating, sealing, and archiving.
- Remove Stopwords
Remove common words in sentences with low informative value. These common words are considered irrelevant and may introduce unwanted noise into text analysis.
The subsection of letters is tasked with handling general affairs, letters, duplication, sealing, and archiving.
Topic Modeling
The obtained sentences need to be paired with other sentences for checking inconsistencies between those sentence pairs. The total number of extracted sentences for all document datasets is 11,144 sentences. Pairing sentences in the entire sentence dataset would result in a very large number of sentence pairs, specifically 6,368,796 sentence pairs. Two issues arise from this. Firstly, this approach is not scalable, as adding a new dataset would double the time complexity of the model prediction. Secondly, the sentence pairs would have significantly different contextual discussions, potentially reducing the model's performance.
To address these issues, topic modeling is performed for each document. The goal of topic modeling is to group documents with high topic similarity. Documents in the same cluster can be considered to have similar subtopics, reducing the checking of inconsistencies between sentences in each document to sentence pairs between documents in the same cluster.
The topic modeling in this study utilizes the BERTopic model. This model is based on the transformer architecture of the BERT (Bidirectional Encoder Representations from Transformers) to obtain word representations from the text, which is then used to group documents into their respective topic clusters. The clustering results of BERTopic on the legal regulation dataset used in this study can be seen in the image below.
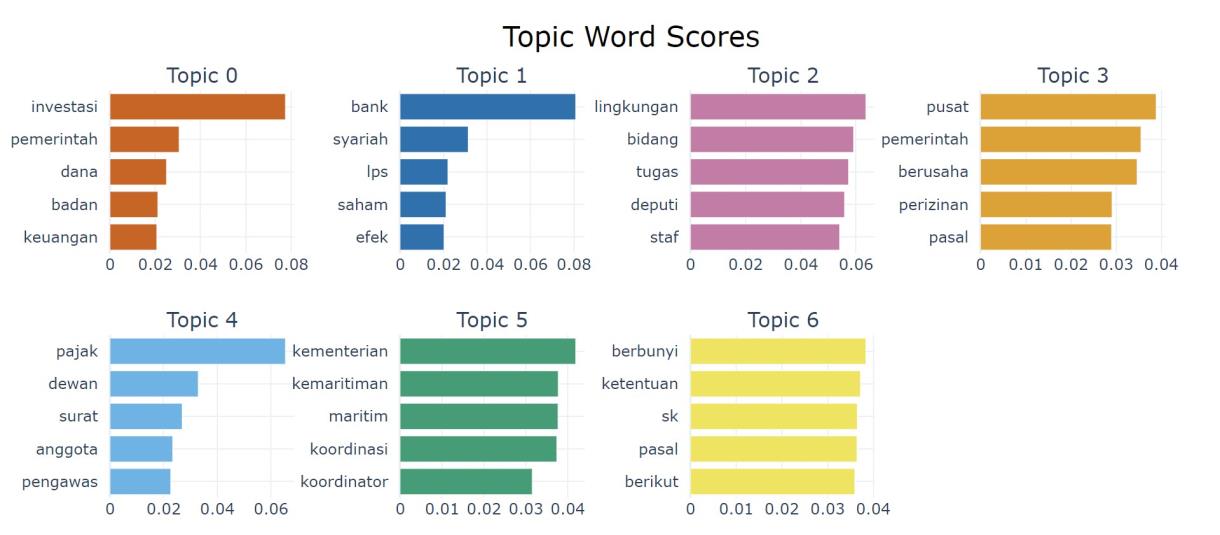
The total clustering BERTopic on this legal regulation dataset reaches 47 topics, with a complete distribution of topic clustering available in the attached documents. It can be observed that 'Topic 0' contains words such as investment, government, funds, agencies, and finance, indicating that this topic broadly discusses "Government Regulations in Managing Investment, Funds, and Financial Affairs of Business Entities." On the other hand, 'Topic 1' discusses "The Role of Conventional and Sharia Banks, as well as LPS in Regulating Stocks and Financial Securities," with words such as banks, Sharia, LPS, stocks, and securities suggesting the general outline of this topic.
With the clustering from BERTopic, a collection of sentences discussing the same topic is obtained. Next, to obtain sentence pairs that are more similar (with more specific discussions), cosine similarity method is used in the next step.

Cosine Similarity
Cosine similarity calculation is used to measure the structural similarity between each pair of sentences within the same topic cluster. The purpose of computing cosine similarity is to provide additional criteria for sentence pairs (in obtaining sufficiently similar pairs) that will enter the model. Cosine similarity in this study uses the tokenizer from the pretrained Indobert model, which has been trained using a large Indonesian language corpus. The result of this tokenizer is a token representation for each word, where each token is represented as a vector in vector space. The calculation of cosine similarity is obtained from Equation 3.1.
Cosine similarity is measured by how much two vectors have the same direction in vector space. This involves the dot product of vectors (A · B) and the calculation of the length of each vector ||A|| and ||B||. The cosine similarity result is in the range of -1 to 1, where a value of 1 indicates the same direction (similar), and a value of -1 indicates the opposite direction (not similar). Examples of sentence pairs with high to low similarity values are represented in the table below.
| Text 1 | Text 2 | Similarity |
|---|---|---|
| A company in the industry that does not meet the provisions as stipulated in Article 7 paragraph (1) or a company in the industry that does not have an expansion permit as stipulated in Article 24 paragraph (1) is known to have administrative sanctions: a. written warning; b. administrative fines; c. temporary closure; d. freezing of the business permit; and/or e. revocation of the business permit | A company in the industry that does not have a business permit as stipulated in Article 2 paragraph (1) is known to have administrative sanctions: a. written warning; b. administrative fines; and c. temporary closure. | 0.9118 |
| (1) The minister, governor, and regent/mayor in accordance with their authority impose administrative sanctions as referred to in Article 30 on industrial companies. | Payment of administrative fines as referred to in paragraph (1) shall be made no later than 30 (thirty) days from the receipt of the administrative fine imposition letter. | 0.7559 |
| Payment of administrative fines as referred to in paragraph (1) shall be made no later than 30 (thirty) days from the receipt of the administrative fine imposition letter. | In order to deepen the structure and improve the competitiveness of the industry, the head of the government agency providing integrated one-stop services in issuing business permits refers to the investment policy in the industrial sector set by the minister. Chapter IV Procedures for granting business permits Part One Small business permits | 0.4045 |
Before these sentence pairs are used in the model, a cosine similarity threshold of 0.75 is used to filter out sufficiently similar sentence pairs. However, the use of cosine similarity alone is not sufficient to obtain semantic relations between sentences that are more complex, such as relations between contradictory sentences. Therefore, its use is limited to ensuring that sentence pairs have the same or relevant similarities.
Model Formation
The developed model is a Natural Language Inference (NLI) model designed to analyze semantic inference relations to detect inconsistencies between pairs of sentences. The development of this model consists of several stages:
Pretrained Model
In the study, the mDeBERTa-v3-base model architecture is used. The mDeBERTa model (Decoding-enhanced BERT with disentangled attention) is a Transformer-based model architecture that introduces enhancements to the BERT and RoBERTa layers, using two techniques. The first technique involves the use of disentangled attention mechanisms to represent two vectors encoding content and position, and attention weights between words are calculated using separate matrices based on their content and relative positions. The second technique involves the use of an optimized mask decoder to incorporate absolute positions in the decoding layers for predicting hidden tokens.
This architecture was developed by Microsoft using the CC100 multilingual dataset containing 100 languages. The research uses a pretrained model based on this architecture, fine-tuned on the XNLI dataset and the multilingual-NLI-26lang-2mil7 dataset, with the downstream NLI task and labels being entailments, neutral, and contradictions. The combination of these two datasets contains 2.7 million sentence pairs in 27 languages, including Indonesian (Weizhu Chen, P. H. J. H. (2023)).
Fine-tune First Model
The pretrained model used is a multilingual model capable of handling sentences in various languages. To achieve better results by specifying the problem in this research, the model undergoes a fine-tuning stage on the indoNLI, SNLI, and MNLI datasets that have been translated into Indonesian. The total combined dataset of these three datasets contains 1 million sentence pairs. This general dataset includes everyday sentence pairs with corresponding labels. The purpose of this fine-tuning process is to create an NLI model that can better understand the semantic relations of Indonesian words, supported by a large dataset of Indonesian NLI.
Generate New Data with ChatGPT
The NLI dataset used in the previous fine-tuning stage contains various sentence pairs with everyday sentence structures. However, in the context of this research problem, the sentence pairs to be used consist of legal clauses from national legislation. The sentence structure of legal clauses has unique characteristics that differentiate them from everyday sentence structures. A comparison between clause sentences and everyday sentences used in the previous NLI dataset can be seen in the table below.
| Clause Sentences | NLI Dataset Sentences |
|---|---|
| The tariff for the services of the Government Investment Center of the Ministry of Finance is compensation for ultra-micro financing services provided by the Government Investment Center of the Ministry of Finance to distributors and/or linkage institutions. | Quite embarrassing, it's all difficulties, laziness, and depressing shapelessness in youth, round pegs in square holes, whatever you want? |
| Cooperation with third parties as referred to in paragraph (1) letter c is carried out by: a. granting or receiving management authority; b. forming a joint venture; or c. other forms of cooperation. | The campaign seems to reach a new group of contributors. |
| Business Actors are individuals or business entities engaged in business and/or activities in a specific field. | He hasn't even seen images like that since some silent films were shown in a few small art theaters. |
Due to the differences in sentence structures, using sentence pairs as a fine-tuning dataset for the model can enhance the model's performance in capturing semantic relations between legal clause pairs.
The collection of legal clause data as a fine-tuning dataset for the model involves manually labeling pairs of sentences in the same topic cluster, with the label choices being 'contradiction' or 'concordance'. In this context, a pair of sentences is considered 'contradictory' if one sentence makes the other sentence incorrect. On the other hand, a pair of sentences is considered 'concordant' if one sentence does not make the other sentence incorrect.
However, there is an issue of imbalanced dataset during the dataset collection process, as the legal clause pairs obtained from legal documents mostly have a 'concordant' relationship, namely 4 'contradictory' and 996 'concordant' data. An imbalanced dataset can lead the model to be biased toward the label with more instances, resulting in a decrease in model performance. Therefore, to obtain sentence pairs with a 'contradictory' relationship, ChatGPT is used to generate synthetic contradictory sentences given a base sentence. An example of the ChatGPT prompt to generate 'contradictory' sentences is shown below.

From the creation of these sentence pairs, a dataset of 1000 'contradictory' labeled pairs and 1000 'concordant' labeled pairs is obtained. This dataset consists of legal clause pairs with their corresponding labels.
Fine-tune Second Model
The model undergoes fine-tuning again using the generated legal clause dataset. The total number of instances in this dataset is 2000 pairs of sentences. This fine-tuned model serves as the final model in the development of the NLI model for classifying national legal clause pairs. The model will classify sentence pairs into two classes: 'concordant' and 'contradictory.'
Model Testing
The main metric used to determine the model's performance in this study is accuracy, calculated based on the number of correct predictions compared to the total number of data. In addition to accuracy, F1 score, recall, and precision metrics are also used to assess the model's performance for each predicted label. The calculation of these metrics follows the formulas below:
The model is tested using the validation dataset from the PUU dataset to check the model's generalization performance on new data. Several testing scenarios are also conducted to test variations in the model development approach, as follows:
- Testing scenario based on the use of cosine similarity with a threshold value of 0.75 for each topic.
- Testing scenario based on variations in the General and PUU datasets.
- Testing scenario based on hyperparameter tuning.
Discussion
The model has been tested with various scenarios and variations in the implemented development approach. Here are the values and results from these tests:
Results of Cosine Similarity Usage Scenario
| Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|
| Without Cosine Similarity | 71.29 | 73.22 | 66.67 | 69.79 |
| With Cosine Similarity | 77.48 | 90.44 | 61.19 | 73.00 |
Testing was conducted based on the scenario of using cosine similarity calculation in the selection of sentence pairs before entering the model. The goal of this scenario is to observe the impact of cosine similarity on pairs of sentences with high semantic structural similarity. The threshold value used as the similarity limit for sentence pairs is 0.75 for each topic cluster. The model used in this stage still employs the first fine-tuned model since the second fine-tuned model will be tested in the next scenario. According to the table above, the model's performance using cosine similarity is better than without cosine similarity, achieving an accuracy of 77.48%.
This is because high cosine similarity values (greater than 0.75) can filter out sentence pairs with high semantic structural similarity. Meanwhile, sentence pairs with low similarity values can be directly considered concordant due to their significantly different semantic sentence structures, indicating different discussion contexts. By eliminating such pairs, it can prevent noise from entering the model, thus helping the model reduce detection errors due to differences in sentence pair contexts.
Results of Dataset Variation Scenario
| Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|
| General Dataset | 77.48 | 90.44 | 61.19 | 73.00 |
| General + PUU | 93.07 | 98.87 | 87.06 | 92.59 |
The next scenario is testing based on the use of different datasets in training the model. The goal of this testing scenario is to assess the impact of adding the PUU dataset to the model's performance. The model variations used include the addition of a dataset using the manually labeled PUU dataset with ChatGPT assistance. This model's approach already implements cosine similarity before the sentence pair data enters the model. According to the table above, the model's performance using the dataset variation of adding PUU provides significantly better metric values compared to the model without the PUU dataset.
This can be explained because the additional use of the PUU dataset provides the model with additional training data that shares characteristics of sentence structure similar to sentences in PUU documents. The model can capture semantic relations between words in legal clauses more effectively than the model without the PUU dataset. The use of PUU dataset variation is crucial in making the model more robust to the issues faced in this study, namely legal clauses.
Results of Hyperparameter Tuning Scenario
| Learning Rates | Batch Size | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| 1e-5 | 6 | 92.33 | 98.30 | 86.07 | 91.78 |
| 1e-5 | 8 | 92.57 | 98.86 | 86.07 | 92.02 |
| 2e-5 | 6 | 92.33 | 97.75 | 86.57 | 91.82 |
| 2e-5 | 8 | 93.07 | 99.43 | 86.57 | 92.55 |
| 5e-5 | 6 | 93.07 | 100.00 | 86.07 | 92.51 |
| 5e-5 | 8 | 91.83 | 97.19 | 86.07 | 91.29 |
The last testing scenario involves testing hyperparameter tuning to find the model parameters that yield the highest performance. The parameter values used for checking combinations are learning rates of 1e-5, 2e-5, 5e-5, and batch sizes of 4, 6, 8. The selection of these hyperparameter values is based on testing the model on a small dataset sample (first fine-tuned model). According to the table above, the most optimal hyperparameter values are a learning rate of 2e-5 and a batch size of 8.
This result is due to the limited number of PUU datasets, making a small batch size more suitable for obtaining contextual data. Additionally, using a small learning rate results in better performance since the previous model has already been fine-tuned, and the weight values are closer to optimal. Using a small learning rate provides more detailed information during the training phase, leading to more stable weight positions compared to the model from the previous fine-tuning stage.
Prediction Results on All Documents
Based on all the testing scenarios conducted, the model with the best performance is used for predictions on the entire dataset of 110 PUU documents. Before using the model, this dataset underwent the preprocessing steps explained in the methodology section, including preprocessing sentence pairs, clustering based on topic modeling, and selection using cosine similarity with a threshold of 0.75. Next, the sentence pair data underwent prediction to detect inconsistencies in the relationships between these sentence pairs. The image below shows the distribution of detected inconsistent sentence pairs based on topics.

The model's prediction results also include information about the inconsistent sentence pairs detected. An example of the table data obtained from the model regarding detected inconsistent sentence pairs can be seen in the image below. A comparison of these sentence pairs can be seen below.
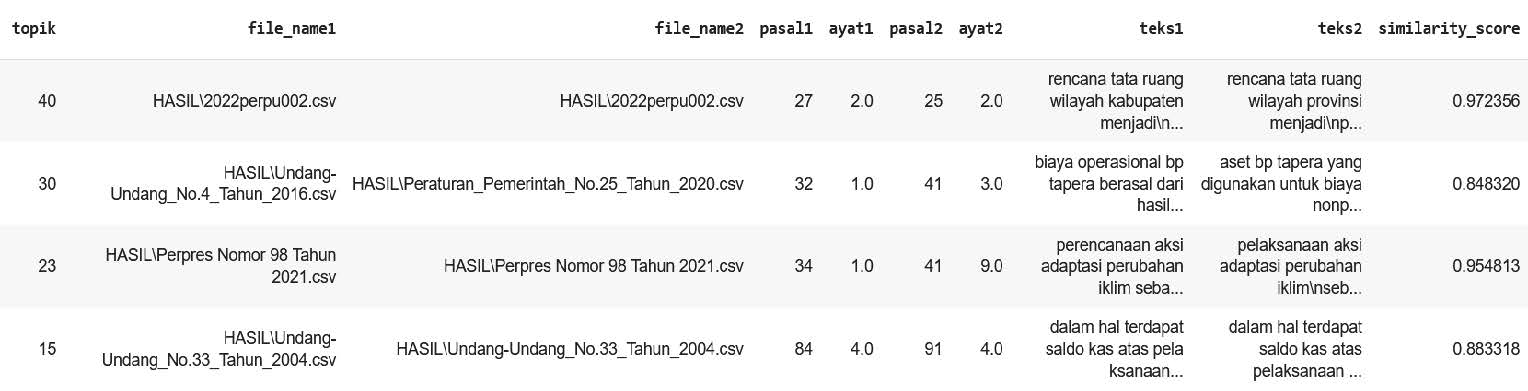
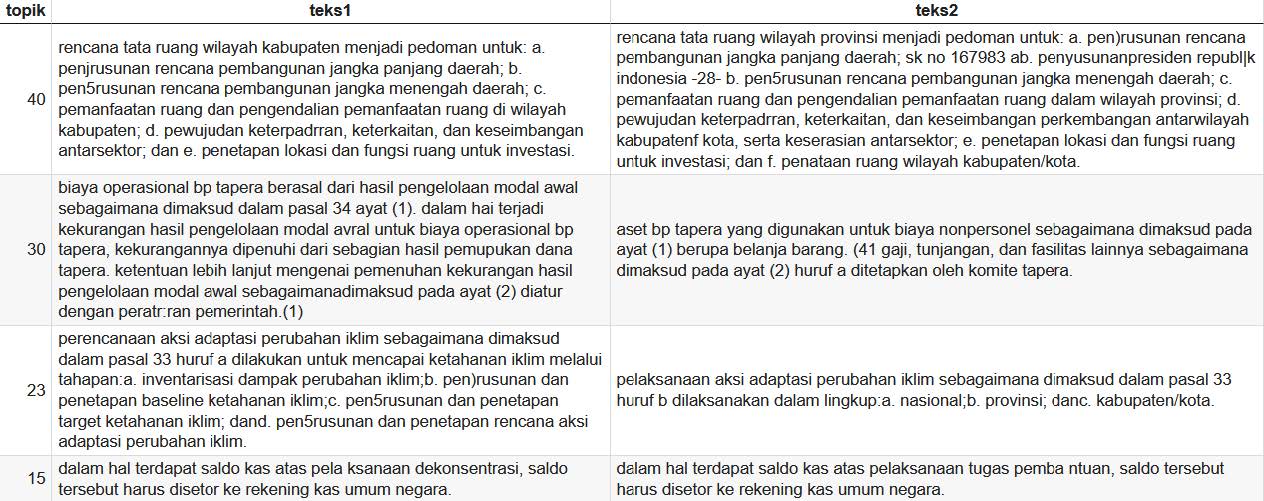
Explanation of Prediction Results
Based on the distribution of detected inconsistent sentence pair data shown in the image above, several clusters have a significantly higher number of inconsistent data than others. This is because these clusters contain a large number of documents, leading to a greater variety of sentence pair combinations and a higher probability of detecting inconsistencies.
The image above is an example of detected inconsistent sentence pair data. It can be observed that these sentence pairs have similar sentence structures. However, there are differences in semantic relations between sentences, indicated by differences in several words. These differences typically occur in sentence subjects, sentence objects, and negation words. These differences are what the model captures to detect inconsistencies between sentence pairs.
Conclusion
This study aimed to detect inconsistencies in Indonesian legal regulations using the BERTopic and mDeBERTa methods. The data used in this study consisted of 110 documents (pdf and docx) of national investment-related legal regulations with various types, years, and levels. The data was extracted and then preprocessed, including lowercasing, link removal, spell-checking, stemming, and stopword removal. Topic modeling and cosine similarity were then applied to produce combinations of sentences with a high level of similarity, i.e., with a threshold of 0.75 (cosine similarity value).
From the model testing results with cosine similarity usage scenarios, it was found that using cosine similarity (to filter datasets) before entering the model can enhance the model's performance in detecting inconsistencies between sentences. The use of the PUU dataset for fine-tuning the model also proved to help the model better understand the semantic relations in legal clause data, resulting in an accuracy of 93.07%. Hyperparameter tuning was also performed on the model to find the best combination of hyperparameters. The optimal hyperparameter combination, with a batch size of 8 and a learning rate of 2e-5, produced the best-performing model, with accuracy, precision, recall, and f1-score values of 93.07%, 99.43%, 86.57%, and 92.55%, respectively.
Recommendations
For future research, experimentation with testing scenarios for the cosine similarity threshold hyperparameter could be conducted. Additionally, the use of a larger dataset could improve the model's performance in predicting inconsistencies in legal regulations. Exploring POS tagging further to determine sentence subjects and objects could help capture relations between PUU sentences.
References
[1] Bayu, D. (2022, August 18). Hari Konstitusi, Berapa Jumlah Peraturan di Indonesia? DataIndonesia.id. Retrieved August 1, 2023, from Hari Konstitusi, Berapa Jumlah Peraturan di Indonesia? dataindonesia.id.
[2] Mahendra, A. O. (2010, March 29). Artikel Hukum Tata Negara dan Peraturan Perundang-undangan. Ditjenpp.Kemenkumham.go.id. Retrieved August 1, 2023, from https://ditjenpp.kemenkumham.go.id/index.php?option=com_content&view=article&id=421:harmonisasi-peraturan-perundang-undangan&catid=100&Itemid=180&lang=en.
[3] Susetio, W. (2013). DISHARMONI PERATURAN PERUNDANG-UNDANGAN DI BIDANG AGRARIA. Disharmoni Peraturan Perundang-Undangan di Bidang Agraria, 1-14. https://media.neliti.com/media/publications/18020-ID-disharmoni-peraturan-perundang-undangan-di-bidang-agraria.pdf
[4] Wahyuni, W. (2023, February 7). 2 Lembaga yang Berwenang Menguji Peraturan Perundang-undangan. Hukumonline.com. Retrieved August 1, 2023, from https://www.hukumonline.com/berita/a/2-lembaga-yang-berwenang-menguji-peraturan-perundang-undangan-lt63e20c084d65a/
[5] Florence Sedes, M. M. J. K. (2018). Using K-Means for Redundancy and Inconsistency Detection: Applivation to Industrial Requirements. Article, 1. https://doi.org/10.1007/978-3-319-91947-8_52
[6] Huang, X. (2021). Detecting inconsistencies of safety artifacts with Natural Language Processing. Article. https://gupea.ub.gu.se/bitstream/handle/2077/74542/thesis_XuniHuang.pdf?sequence=1
[7] Fahrurrozi Rahman, R. M. A. F. S. L. A., Clara Vania (2021). IndoNLI: A Natural Language Inference Dataset for Indonesian. Article. https://doi.org/
[8] Nafide Sadat Moosavi, P. A. U. J. B., Iryana Gurevych (2022). Falsesum: Generating Document-level NLI Examples for Recognizing Factual Inconsistency in Summarization. Article. https://doi.org/
[9] Budianto, V. A. (2022, April 26). 3 Asas Hukum: Lex Superior, Lex Specialis, dan Lex Posterior Beserta Contohnya. Https://www.Hukumonline.com/. Retrieved August 1, 2023, from https://www.hukumonline.com/klinik/a/3-asas-hukum--ilex-superior-i--ilex-specialis-i--dan-ilex-posterior-i-beserta-contohnya-cl6806/
[10] Weizhu Chen, P. H. J. H. (2023). DEBERTAV3: IMPROVING DEBERTA USING ELECTRA-STYLE PRE-TRAINING WITH GRADIENTDISENTANGLED EMBEDDING SHARING. Article. https://doi.org/