- Published
Sentimen Analisis dengan Ekpansi Kueri menggunakan YAKE dan FastText
- Published
- Gaudhiwaa Hendrasto dan Izzati Mukhammad
Penelitian ini bertujuan untuk mendalami penggunaan metode ekspansi kueri dengan menggunakan Yake dan FastText pada dataset Twitter dalam meningkatkan analisis sentimen. Ekstraksi kata kunci dilakukan menggunakan Yake, algoritma yang dapat mengekstraksi kata kunci dari sebuah teks. Adapun FastText digunakan dalam memperluas kata kunci dan memperkaya representasi teks yang telah diekstraksi. Berbagai skenario praproses, skenario pengujian dan penggunaan kamus Indonesia Sentiment Lexicon (InSet) diimplementasikan untuk membandingkan metode mana yang dapat meningkatkan kualitas hasil analisis sentimen. Pada kasus ini prediksi sentimen dilakukan terhadap dua jenis dataset, dataset single-context imbalance dan dataset multi-context balance.
Dengan mempertimbangkan F-1 Score didapatkan bahwa pendekatan menggunakan Yake dan FastText dengan penambahan kamus InSet memiliki akurasi yang lebih baik dibandingkan penggunaan ekstraksi kueri menggunakan Yake dan atau ekspansi kueri menggunakan FastText saja. Pada penggunaan Yake dan atau FastText saja didapatkan skenario terbaik pada dataset single-context imbalance dan dataset multi-context balance berturut-turut adalah 0,44 dan 0,43. Sedangkan pada penambahan kamus InSet, didapatkan skenario terbaik pada dataset single-context imbalance dan dataset multi-context balance berturut-turut adalah 0,47 dan 0,45.
Kata Kunci: FastText , Query Expansion, Sentiment Analysis, Yet Another Keyword Extractor
Latar Belakang
Media sosial memiliki peran penting dalam penyebaran informasi di Indonesia. Menurut laporan We Are Social, pada Januari 2023, terdapat 167 juta pengguna aktif media sosial di Indonesia, yang setara dengan 60,4% dari populasi di dalam negeri (Ali, 2023). Twitter menjadi salah satu media sosial yang banyak digunakan di Indonesia, dengan jumlah pengguna mencapai 14,75 juta pada April 2023, menempati peringkat keenam di dunia (Katadata, 2023) Pengguna Twitter dapat berbagi informasi melalui platform ini dengan cara menyebarkan post dengan pengikut, melalui komentar, ataupun melakukan repost untuk menyebarkan postingan lebih luas. Melalui media sosial, pengguna dapat berpartisipasi, berinteraksi, berbagi, atau terlibat dalam jaringan sosial tanpa dibatasi oleh ruang dan waktu.
Media sosial, khususnya Twitter, dapat digunakan dalam analisis sentimen menggunakan kecerdasan buatan, terutama Natural Language Processing (NLP). Salah satu metode analisis sentimen yang dapat digunakan adalah lexicon based, yang melibatkan penghitungan skor sentimen keseluruhan teks berdasarkan skor sentimen dari kata penyusunnya. Melalui analisis sentimen di media sosial, pengguna dapat mengevaluasi sentimen positif, negatif, atau netral terhadap suatu topik atau tokoh.
Dalam analisis sentimen, terdapat dua metode yang sering digunakan, yaitu metode supervised learning dan metode berbasis leksikon. Meskipun metode berbasis leksikon cenderung lebih mudah diaplikasikan, kelemahan penggunaan kamus leksikon yang tersedia adalah membutuhkan keterlibatan manusia dalam proses pembuatan kamus dan kurang akurat dalam mengidentifikasi konteks dan makna kata dalam kalimat. Sementara itu, metode supervised learning menggunakan algoritma machine learning untuk mengklasifikasikan sentimen berdasarkan data latih yang telah diberi label. Meskipun memerlukan waktu dan sumber daya yang lebih banyak untuk mempersiapkan data latih, metode supervised learning cenderung lebih akurat dalam mengidentifikasi sentimen karena dapat memperhitungkan konteks dan makna kata dalam kalimat. Oleh karena itu, dalam memilih metode analisis sentimen, pengguna harus mempertimbangkan kelebihan dan kelemahan masing-masing metode dan memilih metode yang paling sesuai dengan kebutuhan analisis sentimen yang diinginkan.
Pada penelitian ini, dalam menganalisis sentimen, akan diterapkan metode berbasis leksikon menggunakan Yake dan FastText. Model Yake akan digunakan untuk mengekstraksi kata kunci dari sebuah kalimat teks. Selanjutnya, kata kunci yang telah diekstraksi oleh Yake akan diekspansi oleh FastText, menghasilkan kueri yang mirip secara makna kata. Adapun kamus Indonesia Sentiment Lexicon (InSet) digunakan sebagai skenario uji coba untuk membandingkan hasil akurasi dan F-1 score. Diharapkan pengujian yang dilakukan pada penelitian ini dapat memberikan wawasan terhadap penggunaan metode leksikon berbasis ekstraksi kata kunci menggunakan Yake dan ekspansi kueri menggunakan FastText.
Tujuan
Tujuan kerja praktik ini adalah untuk meningkatkan akurasi analisis sentimen menggunakan pendekatan berbasis leksikon, yaitu ekstraksi kata kunci menggunakan Yake dan ekspansi kueri menggunakan FastText.
Manfaat
Manfaat kerja praktik ini adalah memberikan wawasan baru terhadap analisis sentimen menggunakan pendekatan berbasis leksikon dengan menggunakan ekstraksi kata kunci dan ekspansi kueri. Hasil penelitian ini diharapkan dapat meningkatkan hasil akurasi analisis sentimen dan dapat digunakan sebagai bahan pertimbangan pada penelitian yang akan datang.
Rumusan Masalah
Dari latar belakang dan tujuan yang telah ditentukan, maka dapat dirumuskan rumusan masalah, sebagai berikut:
Bagaimana pengaruh ekstraksi kata kunci dan atau ekspansi kueri terhadap performa metode Lexicon-Based?
Bagaimana pengaruh penambahan kamus InSet terhadap performa metode ekstraksi kata kunci dan ekspansi kueri?
Metodologi
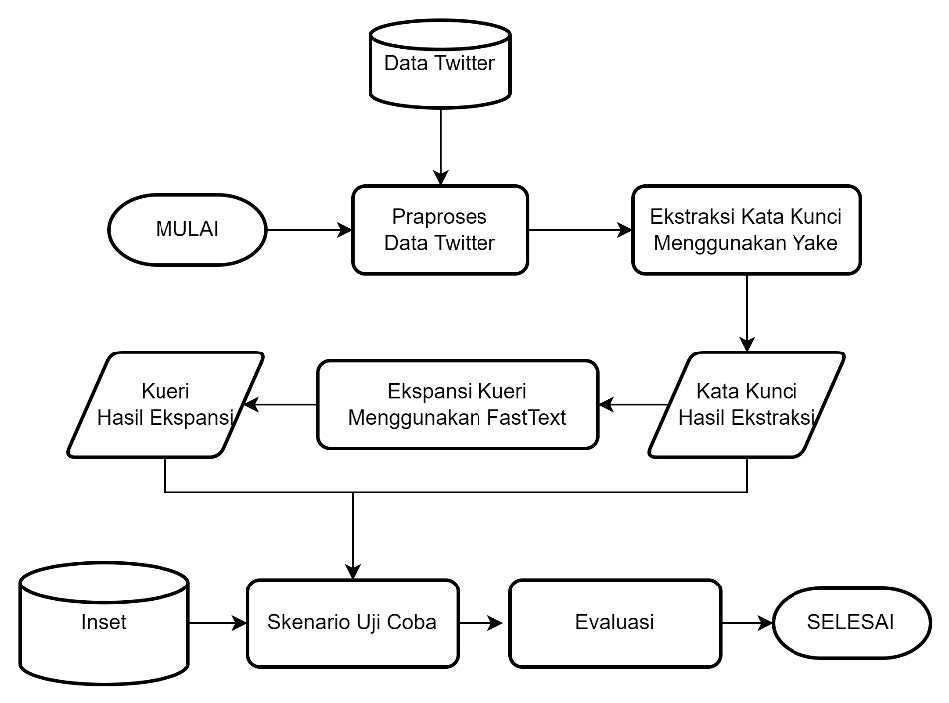
Pada kerja praktik ini akan dibuat sebuah sistem yang dapat meningkatkan akurasi sentimen analisis menggunakan pendekatan ekstraksi kata kunci dan ekspansi kueri menggunakan Yake dan FastText. Dataset yang digunakan merupakan dua buah dataset Twitter yang telah di-scrapping dan telah dianotasi dengan sentimen positif, netral, dan negatif. Kedua dataset tersebut memiliki perbedaan karakteristik data, sehingga pada penelitian kali ini dataset tersebut dipisah, dan diberi nama dataset A (single-context imbalance) dan dataset B (multi-context balance). Kemudian dataset Twitter yang telah didapatkan akan dilakukan beberapa tahapan guna mendapatkan hasil sentimen. Adapun tahapan-tahapan yang dilakukan yakni: praproses, ekstraksi kata kunci menggunakan Yake, ekspansi kueri menggunakan FastText, penggunaan InSet, melakukan skenario praproses, melakukan skenario uji coba, serta tahapan akhir yaitu evaluasi. Pada evaluasi akan dilakukan penilaian sentimen analisis berdasarkan akurasi dan F-1 score. Adapun diagram alir mengenai metode penelitian ini dapat dilihat pada Gambar di bawah.
Dataset ini terdiri dari dataset A dan dataset B, dengan total data secara berturut-turut adalah 61.732 dan 42.692 baris data. Persebaran sentimen kedua dataset dapat dilihat pada Tabel 4.1 dan 4.2. Perlu dicermati bahwa pada dataset A terdapat ketidakseimbangan data, di mana persebaran data positif, negatif, dan netral cenderung tidak seimbang. Dalam tahap evaluasi, ketidakseimbangan data dapat memungkinkan terjadinya perbedaan akurasi yang cukup signifikan.
| Sentimen | Jumlah | Persentase |
|---|---|---|
| Positif | 9.818 | 15,90% |
| Netral | 23.075 | 37,37% |
| Negatif | 28.839 | 46,71% |
| Total | 61.732 | 100% |
| Sentimen | Jumlah | Perbandingan |
|---|---|---|
| Positif | 12.610 | 29,53% |
| Netral | 15.398 | 36,06% |
| Negatif | 14.684 | 34,39% |
| Total | 42.692 | 100% |
Persentase perbandingan sentimen positif, netral, dan negatif pada dataset A secara berturut turut adalah adalah 15,90%, 37,37%, dan 46,71%. Ini menunjukkan bahwa kecenderungan dataset A dominan pada sentimen netral dan negatif. Sedangkan pada dataset B, perbandingan sentimen positif, netral, dan negatif secara berturut turut adalah adalah 15,90%, 37,37%, dan 46,71%, di mana data ini cenderung seimbang.
Adapun contoh dataset A dan dataset B dapat dilihat pada Tabel di bawah.
| No. | Positif | Negatif | Netral |
|---|---|---|---|
| 1 | Kualitas Anies memang di atas 2 capres lainnya. Simpel aja kok ..kita lihat saja rekam jejaknya. Lihat dari narasumber yg sahih , bukan dari buzzer . | Sama dok, saya gerah juga lihat kelakuan yg jabat skrg malahan sibuk urusan copras/capres.harusnya selesaikan janjinya, tinggal 9bln lagi loo. | Bolehkah oposisi menyiapkan capres? Boleh saja. Yang gak boleh merasa dicurangi sebelum bertanding. |
| 2 | KPU meyakinkan tahapan demi tahapan pemilu dilakukan sesuai UU dan akan diselenggarakan tepat waktu, yakni 14 Februari 2024. | Setujuu.. mereka Oligardan ingin capres bonekaa lagi.... | SBY mau jadi capres y? |
| 3 | Contoh capres yang gak suka selfie dan posting foto di medsos | Norak lu Den,...apa yang dilakukan Ganjar sudah dilakukan Anies saat jadi gubernur,nah ini Ganjar mau jadi capres,baru action biar dianggap kerjanya bagus | PKB mengusung Prabowo Subianto jadi capres - ANTARA Sulawesi Utara |
| 4 | punchline yg duarr banget pak capres | Dari pada capres anda gagal pimpin Jateng | Udah bisa lah jadi capres |
| 5 | Antusias masyarakat Banten sambut Ganjar Pranowo capres 2024 | Berarti presiden sekarang sibuk nya lagi ngurus copras capres bukan ngurusin kerjasama bilateral | Sttment di awal, biar nnti klo gagal jadi capres gak malu.. |
| No. | Positif | Negatif | Netral |
|---|---|---|---|
| 1 | Pemerintah tetap berkomitmen untuk menjalankan pemilu sesuai tahapan | Kita dah buat yang terbaik tapi masih tetap rasa kecewa | Ya Allah pengen ngakak goler-goler aku sama trit ini |
| 2 | Pemilu 2024 akan tetap sesuai jadwal! | Setujuu.. mereka Oligardan ingin capres boneka lagi.... 😅😅 | Barusan liat tulisan di belakang truk rela injek kopling demi kamu bisa shopping |
| 3 | Sdhlah kamu dan anak-anak. | Tak kunjungi korban gempa nanti malah merepotkan tim gabungan TNI, Polisi, AMP, Basarnas perl | Aku tadi nge-RT wah wah wah |
| 4 | Kita buktikan aja nanti di pilpres 2024 biar gua ga pernah nyoblos pemilu tp gua yakin Anies yg akan menang | Warga Donggala membantah ada penjarahan kepada Antara yang menjadi media pertama yang menemui mereka, mereka mengharapkan | Izinkan aku mengupload ini |
| 5 | Peluang Duet Airlangga-Puan Terbuka | Jokowi pembohong | Sama aku kapan |
Kedua dataset berisi cuitan twitter yang cenderung nonformal. Adapun karakteristik lainnya pada kedua dataset ini, yaitu: terdapat singkatan-singkatan kata, bahasa inggris, dan emotikon. Secara semantik, dataset B bersifat multi-konteks. Ini memungkinkan terjadinya perbedaan akurasi antara kedua dataset.
Praproses
Semua data akan dilakukan serangkaian tindakan praproses, seperti mengonversi teks ke huruf kecil, menghilangkan mention, hashtag, nomor telepon, tautan, emotikon, tanda baca, angka, kata-kata slang, kombinasi kata, kata-kata yang tidak relevan (stopwords), pengubahan kata menjadi kata baku (stemming), dan juga diterjemahkan ke dalam bahasa Indonesia. Adapun penjelasan terkait praproses yang digunakan sebagai berikut:
Mengubah menjadi huruf kecil: Dilakukan perubahan huruf kapital menjadi huruf kecil.
Penghapusan mention, hashtag, nomor telepon, dan tautan: Bagian-bagian yang disebutkan tidak berkaitan dengan analisis sentimen yang dilakukan, sehingga lebih baik untuk dihapus.
Penghapusan emotikon: Emotikon merupakan ilustrasi karakter yang menunjukkan ekspresi wajah, sikap, atau emosi. Namun, penggunaan emotikon tidak sepenuhnya menggambarkan sentimen dari Twitter, bahkan dapat berlawanan atau sarkasme. Oleh sebab itu, dilakukan penghapusan emotikon.
Penghapusan tanda baca: tanda baca seringkali tidak membawa informasi sentimen yang signifikan pada analisis sentimen. Analisis sentimen lebih berfokus pada kata-kata, frase, atau struktur kalimat yang mengandung sentimen positif, negatif, atau netral.
Penghapusan angka: Angka berupa digit umumnya digunakan untuk menyatakan tahun, nomor, dan lain-lain. Data Twitter yang digunakan dalam penelitian ini memiliki konteks yang berbeda-beda, sehingga penggunaan angka dalam analisis sentimen dapat membuat bias angka pada konteks yang berbeda.
Penghapusan kata alay: Kata alay merupakan kata yang berlebihan, dan cukup sering ditemukan pada platform Twitter. Perubahan kata alay menjadi formal bertujuan untuk memproses kata bermakna sama untuk dapat diberlakukan sama, sebagai contoh kata yg dan yang.
Penghapusan gabungan kata: Dalam hal ini kata gabungan sering digunakan, seperti can’t yang berarti can not. Tahapan ini berguna agar kata gabungan dapat diberlakukan sama dengan kata penyusunnya.
Penghapusan stopwords: Stopwords merupakan kata dengan makna yang kurang berarti, sehingga keberadaannya tidak diperlukan. Selain itu, penghapusan stopwords juga dapat meminimalkan waktu komputasi yang diperlukan.
Stemming: merupakan proses penghapusan imbuhan pada kata menjadi bentuk dasarnya. Tahapan ini berguna menghindari variasi dari kata, dan membuat kata dengan bentuk imbuhan berbeda dapat diberlakukan sama.
Penerjemaan ke bahasa Indonesia: Di dalam dataset yang digunakan, terdapat beberapa cuitan berbasa bahasa Inggris dan berbahasa Indonesia, sehingga diperlukan penerjemahan.
| No. | Teknik Praproses | Teks |
|---|---|---|
| 1 | Teks Asli | Mudah-mudahan kita pilih capres yang benar, partai yang benar," seru Muzani. |
| 2 | Huruf Kecil | mudah-mudahan kita pilih capres yang benar, partai yang benar," seru muzani. |
| 3 | Penghapusan Emoji | mudah-mudahan kita pilih capres yang benar, partai yang benar," seru muzani. |
| 4 | Penghapusan Tanda Baca | mudahmudahan kita pilih capres yang benar partai yang benar seru muzani |
| 5 | Penghapusan Angka | mudahmudahan kita pilih capres yang benar partai yang benar seru muzani |
| 6 | Penghapusan Kata-kata Alay | mudahmudahan kita pilih capres yang benar partai yang benar seru muzani |
| 7 | Penghapusan Gabungan Kata | mudahmudahan kita pilih capres yang benar partai yang benar seru muzani |
| 8 | Penghapusan Stopwords | mudahmudahan pilih capres partai seru muzani |
| 9 | Stemming | mudahmudahan pilih capres partai seru muzani |
| 10 | Translate | mudahmudahan pilih capres partai seru muzani |
Ekstraksi Kata Kunci menggunakan Yake
Setelah tahap praproses data Twitter, dilakukan ekstraksi kata kunci menggunakan Yake. Ekstraksi kata kunci dilakukan terhadap sentimen positif, netral, dan negatif. Selain itu konfigurasi parameter Yake juga dilakukan guna meningkatkan performa secara optimal. Parameter Yake yang digunakan adalah ngram=1, windowSize=1, dedupLim=0.9, dedupFunc=’seqm’, dan top=100.
Pada tahap ini juga diimplementasikan Part of Speech (POS) tagging, di mana hanya kata sifat (j) dan kata kerja (v) yang akan diekstrak kata kuncinya. Adapun kata benda (n) tidak dimasukkan untuk diesktrak, karena jika dibandingkan dengan kata sifat dan kata kerja, hasilnya tidak begitu signifikan. Hal ini juga untuk mengoptimalkan agar ekstraksi kata kunci pada suatu sentimen tidak menghasilkan kata kunci di luar sentimen tersebut.
Beberapa daftar kata juga ditambahkan secara manual pada setiap sentimen agar daftar kata tersebut tidak dimasukkan ke dalam hasil ekstraksi kata kunci sentimen. Adapun contoh daftar kata yang tidak dimasukkan adalah sebagai berikut:
delete_this_keyword_neutral = [‘salah’, ‘kayak’, ‘wkwk’, …] delete_this_keyword_positive= [‘serentak’, ‘lupa’, ‘aneh’, …] delete_this_keyword_negative = [‘coba’, ‘cari’, ‘butuh’, …]
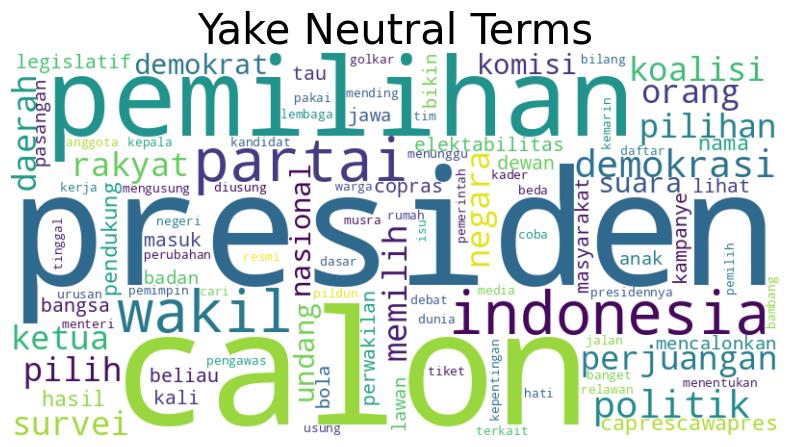
Setelah dilakukan ekstraksi, didapatkan 100 kata kunci tertinggi pada setiap sentimen. Hasil dari kata kunci yang telah diekstrak pada sentimen positif, netral, dan negatif dapat dilihat pada Gambar 4.2, 4.3, dan 4.4. Hasil tersebut merupakan hasil ekstraksi dari dataset A pada salah satu skenario uji coba.


Ekspansi Kueri Menggunakan FastText
Setelah tahap ektraksi kata kunci, selanjutnya dilakukan ekspansi untuk mendapatkan kata-kata yang similar atau mirip dengan kata yang telah diekstraksi. Model FastText yang digunakan berasal dari website resmi FastText, pada model yang digunakan sudah terdapat kosa kata bahasa indonesia lengkap yang sudah dilatih dari dataset Common Crawl dan Wikipedia, oleh karenanya dalam penelitian ini menggunakan model tersebut dan menggunakan fitur fitur ekspansi kueri yang sudah ada didalamnya seperti menampilkan kata kata yang mirip atau saling berhubungan bedasarkan nilai dari vektor kata kunci tersebut ditambah dengan proses preproses dalam pemilihan kosa kata yang akan diambil yaitu berupa kata yang tidak memiliki tanda baca. Gambar di bawah menunjukkan representasi hasil dari ekspansi kueri menggunakan FastText.
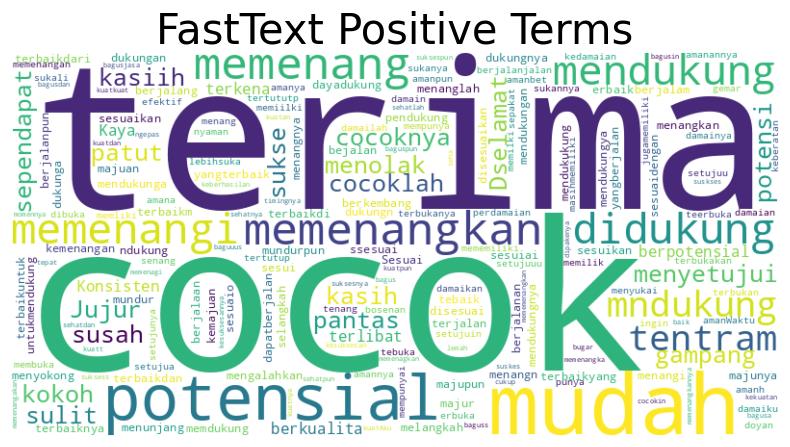

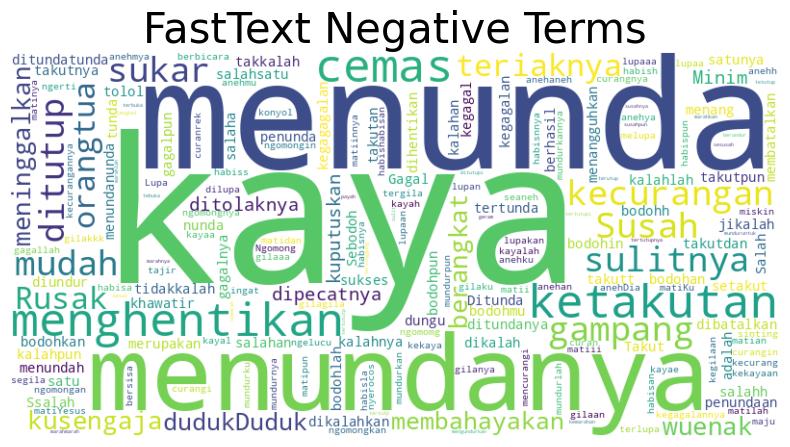
Kamus Indonesia Sentiment Lexicon (InSet)
Kamus InSet dipakai sebagai salah satu uji coba skenario. Kamus ini terdiri dari 3.610 kata positif dan 6.610 kata negatif, dengan masing-masing kata pada sentimen memiliki bobot yang berbeda-beda. Bobot pada kamus ini berkisar antara -5 sampai dengan 5, di mana minus menyatakan kata negatif dan positif menyatakan kata positif. Kamus ini akan membantu pendeteksian sentimen pada teks di dataset, di mana kata-kata yang terdeteksi akan dijumlahkan bobotnya. Pada umumnya, teks dengan jumlah bobot positif akan menjadi sentimen positif dan teks dengan jumlah bobot negatif akan menjadi sentimen negatif. Berikut pada Tabel 4.6 dan 4.7 menunjukkan beberapa contoh bobot dari masing-masing sentimen pada kamus InSet.
| No. | Word | Weight |
|---|---|---|
| 1 | terimakasih | 5 |
| 2 | promo | 3 |
| 3 | mohon | 2 |
| 4 | lebar | 3 |
| 5 | sesal | -4 |
| 6 | pengen | -2 |
| 7 | linu | -4 |
| 8 | ngga | -2 |
Skenario Uji Coba
Pada penelitian ini dilakukan tiga skema skenario uji coba. Skenario uji coba penelitian ini terdiri dari tujuh skenario praproses, lima skenario pengujian, dan tiga skenario threshold. Berikut merupakan deskripsi dari masing-masing skenario:
| No. | Deskripsi |
|---|---|
| 1 | Case folding, hapus link, hapus emoji, hapus tanda baca, hapus nomor |
| 2 | Case folding, hapus link, hapus emoji, hapus tanda baca, hapus nomor, hapus stopwords |
| 3 | Case folding, hapus link, hapus emoji, hapus tanda baca, hapus nomor, hapus stopwords, stemming |
| 4 | Case folding, hapus link, hapus emoji, hapus tanda baca, hapus nomor, hapus kata alay, hapus gabungan kata, translate |
| 5 | Hapus kata alay, hapus gabungan kata, translate |
| 6 | Case folding, hapus link, hapus emoji, hapus tanda baca, hapus nomor, hapus kata alay, hapus stopwords, stemming |
| 7 | Case folding, hapus link, hapus emoji, hapus tanda baca, hapus kata alay, hapus stopwords, hapus gabungan kata |
Pada Tabel 4.8 terdapat tujuh skenario yang berisi tahapan-tahapan praproses yang berbeda-beda. Diasumsikan bahwa tahap praproses berpengaruh terhadap nilai akurasi pada tahap evaluasi. Skenario praproses ini dimaksudkan agar mendapatkan nilai akurasi terbaik. Tahapan-tahapn praproses pada skenario mencakup case folding, hapus link, hapus emoji, hapus tanda baca, hapus nomor, hapus stopwords, stemming, hapus kata alay, hapus gabungan kata, dan translate. Adapun skenario praproses ini akan dikombinasikan dengan skenario pengujian, yaitu skenario evaluasi atau penilaian sentimen analisis.
| No. | Deskripsi |
|---|---|
| 1 | Yake (-1 dan 1), FastText (-1 dan 1) |
| 2 | InSet (-5 s.d. 5), Yake (-1 dan 1), FastText (-1 dan 1) |
| 3 | InSet (-5 s.d. 5), Yake (-5 dan 5), FastText (-5 s.d 5) |
| 4 | InSet (-5 s.d. 5) jika + ketemu + ambil paling besar, Yake (-1 dan 1), FastText (-1 dan 1) |
| 5 | InSet (-1 dan 1), Yake (-1 dan 1), FastText (-1 dan 1) |
| 6 | Yake (-1 dan 1) |
| 7 | FastText (-1 dan 1) |
Pada Tabel 4.9 dijabarkan deskripsi skenario pengujian. Skenario pengujian penting dilakukan sebagai upaya peningkatkan akurasi sentimen analisis menggunakan pendekatan ekstraksi kata kunci Yake, ekspansi kueri FastText, serta kamus InSet. Masing-masing skenario memiliki rentang bobotnya masing-masing, di mana normalnya InSet memiliki kisaran bobot -5 yang menyatakan kata negatif sampai dengan 5 yang menyatakan kata positif. Sedangkan Yake dan Fastext memiliki nilai -1 yang menyatakan kata negatif dan 1 yang menyatakan kata positif. Pada skenario pengujian dilakukan uji coba penggunaan salah satu komponen (Yake atau FastText saja), dua komponen (Yake dan FastText), atau tiga komponen (Yake, FastText, dan InSet). Masing-masing dari tiga komponen tersebut memiliki variasi bobot sentimen yang berbeda-beda.
| No. | Deskripsi |
|---|---|
| 1 | Threshold netral (0) |
| 2 | Threshold netral (-1 s.d 1) |
| 3 | Threshold netral (-2 s.d 2) |
| 4 | Threshold netral (-3 s.d 3) |
Penting untuk mendefinisikan threshold netral pada penelitian ini. karena pada masing-masing tools analisis sentimen bobotnya berbeda-beda. Threshold netral dimaksudkan agar data tidak bias terhadap bobot Yake, FastText, dan InSet. Dengan begitu, diharapkan hasil ini dapat meningkatkan akurasi sentimen netral.
Skenario Uji Coba Dataset A dengan threshold netral 0
| Praproses | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,4 | 0,36 | 0,36 | 0,36 | 0,39 | 0,43 | 0,39 | 0,384 |
| 2 | 0,42 | 0,38 | 0,38 | 0,38 | 0,39 | 0,43 | 0,41 | 0,399 |
| 3 | 0,42 | 0,38 | 0,37 | 0,38 | 0,39 | 0,41 | 0,44 | 0,399 |
| 4 | 0,4 | 0,38 | 0,37 | 0,38 | 0,4 | 0,43 | 0,38 | 0,391 |
| 5 | 0,4 | 0,36 | 0,36 | 0,36 | 0,39 | 0,43 | 0,39 | 0,384 |
| 6 | 0,42 | 0,39 | 0,38 | 0,39 | 0,41 | 0,41 | 0,43 | 0,404 |
| 7 | 0,4 | 0,36 | 0,35 | 0,36 | 0,38 | 0,43 | 0,38 | 0,380 |
| AVG | 0,409 | 0,373 | 0,367 | 0,373 | 0,393 | 0,424 | 0,403 | 0,392 |
Skenario Uji Coba Dataset A dengan threshold netral -1 hingga 1
| Praproses | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,46 | 0,39 | 0,38 | 0,39 | 0,44 | 0,46 | 0,39 | 0,416 |
| 2 | 0,46 | 0,41 | 0,4 | 0,41 | 0,45 | 0,46 | 0,41 | 0,429 |
| 3 | 0,46 | 0,4 | 0,39 | 0,41 | 0,45 | 0,46 | 0,44 | 0,430 |
| 4 | 0,45 | 0,4 | 0,39 | 0,4 | 0,45 | 0,46 | 0,38 | 0,419 |
| 5 | 0,46 | 0,39 | 0,38 | 0,39 | 0,44 | 0,46 | 0,39 | 0,416 |
| 6 | 0,46 | 0,41 | 0,39 | 0,41 | 0,46 | 0,46 | 0,43 | 0,431 |
| 7 | 0,45 | 0,38 | 0,39 | 0,39 | 0,44 | 0,46 | 0,38 | 0,413 |
| AVG | 0,457 | 0,397 | 0,389 | 0,4 | 0,447 | 0,46 | 0,403 | 0,422 |
Skenario Uji Coba Dataset A dengan threshold netral -2 hingga 2
| Praproses | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,46 | 0,41 | 0,4 | 0,41 | 0,46 | 0,46 | 0,46 | 0,437 |
| 2 | 0,47 | 0,43 | 0,41 | 0,43 | 0,46 | 0,46 | 0,46 | 0,446 |
| 3 | 0,46 | 0,43 | 0,41 | 0,43 | 0,47 | 0,46 | 0,46 | 0,446 |
| 4 | 0,46 | 0,42 | 0,41 | 0,42 | 0,46 | 0,46 | 0,46 | 0,441 |
| 5 | 0,46 | 0,41 | 0,4 | 0,41 | 0,46 | 0,46 | 0,46 | 0,437 |
| 6 | 0,46 | 0,43 | 0,41 | 0,43 | 0,47 | 0,46 | 0,46 | 0,446 |
| 7 | 0,46 | 0,4 | 0,39 | 0,4 | 0,46 | 0,46 | 0,46 | 0,433 |
| AVG | 0,461 | 0,419 | 0,404 | 0,419 | 0,463 | 0,46 | 0,46 | 0,441 |
Skenario Uji Coba Dataset A dengan threshold netral -3 hingga 3
| Praproses | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,37 | 0,42 | 0,43 | 0,42 | 0,39 | 0,36 | 0,37 | 0,394 |
| 2 | 0,36 | 0,44 | 0,45 | 0,44 | 0,38 | 0,36 | 0,36 | 0,399 |
| 3 | 0,36 | 0,44 | 0,44 | 0,44 | 0,38 | 0,36 | 0,36 | 0,397 |
| 4 | 0,37 | 0,42 | 0,43 | 0,41 | 0,39 | 0,36 | 0,37 | 0,393 |
| 5 | 0,36 | 0,42 | 0,42 | 0,41 | 0,39 | 0,36 | 0,36 | 0,389 |
| 6 | 0,36 | 0,44 | 0,44 | 0,44 | 0,38 | 0,36 | 0,36 | 0,397 |
| 7 | 0,36 | 0,43 | 0,44 | 0,43 | 0,38 | 0,36 | 0,36 | 0,394 |
| AVG | 0,363 | 0,43 | 0,436 | 0,427 | 0,384 | 0,36 | 0,363 | 0,395 |
Pada dataset A, skenario praproses 6 memiliki nilai akurasi tertinggi di antara semua skenario praproses. Pada skenario pengujian, skenario dengan akurasi tertinggi cenderung silih berganti antara skenario pengujian 5 dan 6. Pada skenario threshold, didapatkan skenario threshold -3 s.d 3 memiliki tingkat akurasi yang paling tinggi.
Skenario Uji Coba Dataset B dengan threshold netral 0
| Praproses | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,42 | 0,4 | 0,42 | 0,4 | 0,41 | 0,43 | 0,39 | 0,410 |
| 2 | 0,43 | 0,43 | 0,44 | 0,43 | 0,42 | 0,43 | 0,39 | 0,424 |
| 3 | 0,41 | 0,43 | 0,42 | 0,42 | 0,42 | 0,43 | 0,38 | 0,416 |
| 4 | 0,41 | 0,4 | 0,41 | 0,4 | 0,41 | 0,42 | 0,38 | 0,404 |
| 5 | 0,42 | 0,4 | 0,4 | 0,4 | 0,4 | 0,43 | 0,38 | 0,404 |
| 6 | 0,41 | 0,43 | 0,43 | 0,43 | 0,42 | 0,42 | 0,38 | 0,417 |
| 7 | 0,42 | 0,43 | 0,43 | 0,42 | 0,42 | 0,42 | 0,38 | 0,417 |
| AVG | 0,417 | 0,417 | 0,421 | 0,414 | 0,414 | 0,426 | 0,383 | 0,413 |
Skenario Uji Coba Dataset B dengan threshold netral -1 hingga 1
| Skenario | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,4 | 0,41 | 0,42 | 0,41 | 0,41 | 0,39 | 0,39 | 0,404 |
| 2 | 0,4 | 0,44 | 0,42 | 0,41 | 0,41 | 0,39 | 0,39 | 0,409 |
| 3 | 0,39 | 0,43 | 0,43 | 0,43 | 0,42 | 0,39 | 0,39 | 0,411 |
| 4 | 0,39 | 0,41 | 0,42 | 0,41 | 0,41 | 0,39 | 0,38 | 0,401 |
| 5 | 0,39 | 0,41 | 0,41 | 0,4 | 0,4 | 0,39 | 0,39 | 0,399 |
| 6 | 0,39 | 0,43 | 0,43 | 0,43 | 0,42 | 0,39 | 0,43 | 0,417 |
| 7 | 0,39 | 0,43 | 0,42 | 0,43 | 0,41 | 0,39 | 0,38 | 0,407 |
| AVG | 0,393 | 0,423 | 0,421 | 0,417 | 0,411 | 0,39 | 0,393 | 0,407 |
Skenario Uji Coba Dataset B dengan threshold netral -2 hingga 2
| Skenario | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,38 | 0,42 | 0,43 | 0,42 | 0,4 | 0,37 | 0,38 | 0,400 |
| 2 | 0,37 | 0,44 | 0,45 | 0,45 | 0,39 | 0,37 | 0,38 | 0,407 |
| 3 | 0,37 | 0,44 | 0,44 | 0,44 | 0,44 | 0,37 | 0,39 | 0,413 |
| 4 | 0,37 | 0,41 | 0,42 | 0,41 | 0,4 | 0,37 | 0,38 | 0,394 |
| 5 | 0,37 | 0,41 | 0,42 | 0,41 | 0,4 | 0,37 | 0,38 | 0,394 |
| 6 | 0,37 | 0,44 | 0,44 | 0,44 | 0,4 | 0,37 | 0,39 | 0,407 |
| 7 | 0,37 | 0,43 | 0,44 | 0,43 | 0,39 | 0,37 | 0,38 | 0,401 |
| AVG | 0,371 | 0,427 | 0,434 | 0,429 | 0,403 | 0,37 | 0,383 | 0,402 |
Skenario Uji Coba Dataset B dengan threshold netral -3 hingga 3
| Skenario | uji1 | uji2 | uji3 | uji4 | uji5 | uji6 | uji7 | AVG |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,37 | 0,42 | 0,43 | 0,42 | 0,39 | 0,36 | 0,37 | 0,394 |
| 2 | 0,36 | 0,44 | 0,45 | 0,44 | 0,38 | 0,36 | 0,36 | 0,399 |
| 3 | 0,36 | 0,44 | 0,44 | 0,44 | 0,38 | 0,36 | 0,36 | 0,397 |
| 4 | 0,37 | 0,42 | 0,43 | 0,41 | 0,39 | 0,36 | 0,37 | 0,393 |
| 5 | 0,36 | 0,42 | 0,42 | 0,41 | 0,39 | 0,36 | 0,36 | 0,389 |
| 6 | 0,36 | 0,44 | 0,44 | 0,44 | 0,38 | 0,36 | 0,36 | 0,397 |
| 7 | 0,36 | 0,43 | 0,44 | 0,43 | 0,38 | 0,36 | 0,36 | 0,394 |
| AVG | 0,363 | 0,43 | 0,436 | 0,427 | 0,384 | 0,36 | 0,363 | 0,395 |
Pada dataset B, skenario praproses dengan nilai akurasi tertinggi silih berganti antara skenario praproses 2, 6, dan 3. Pada skenario pengujian, skenario dengan akurasi tertinggi juga cenderung silih berganti antara skenario pengujian 6, 2, dan 3. Pada skenario threshold, didapatkan skenario threshold 0 memiliki tingkat akurasi yang paling tinggi.
Perbandingan hasil skenario dataset A dan B
Pada dataset A, terlihat jika rentang threshold semakin tinggi, maka nilai akurasi semakin tinggi. Pada dataset B, jika rentang threshold semakin tinggi, maka akurasi semakin rendah. Berikut representasi data akurasi beserta threshold pada Tabel 5.9 dan 5.10.
| No. | Threshold | Akurasi |
|---|---|---|
| 1 | 0 | 0,392 |
| 2 | -1 s.d 1 | 0,422 |
| 3 | -2 s.d 2 | 0,441 |
| 4 | -3 s.d 3 | 0,450 |
| No. | Threshold | Akurasi |
|---|---|---|
| 1 | 0 | 0,413 |
| 2 | -1 s.d 1 | 0,407 |
| 3 | -2 s.d 2 | 0,402 |
| 4 | -3 s.d 3 | 0,395 |
Ini mungkin terjadi karena persebaran dataset A yang imbalance, di mana sentimen netral cenderung tinggi dibandingkan dengan sentimen lainnya. Jika threshold-nya tinggi, kemungkinan prediksi netralnya juga akan tinggi. Dengan demikian ini menjelaskan bahwa mengapa threshold tinggi menyebabkan akurasi tinggi pada dataset B. Sedangkan pada dataset B, persebaran data sentimennya cenderung balance. Dengan demikian, jika threshold-nya semakin tinggi, maka maka probabilitas prediksi netralnya juga akan tinggi. Oleh karena itu, pada dataset B, threshold yang tinggi dapat menyebabkan akurasi yang semakin rendah.
| Skenario | Sentimen | Yake | Total Yake | FastText | Total FastText |
|---|---|---|---|---|---|
| 1 | Positif | 59 | 185 | 552 | 1.719 |
| Negatif | 77 | 719 | |||
| Netral | 49 | 448 | |||
| 2 | Positif | 59 | 185 | 552 | 1.719 |
| Negatif | 77 | 719 | |||
| Netral | 49 | 448 | |||
| 3 | Positif | 29 | 115 | 278 | 1.103 |
| Negatif | 56 | 535 | |||
| Netral | 30 | 290 | |||
| 4 | Positif | 57 | 180 | 529 | 1.682 |
| Negatif | 75 | 705 | |||
| Netral | 48 | 448 | |||
| 5 | Positif | 59 | 185 | 547 | 1.711 |
| Negatif | 77 | 717 | |||
| Netral | 49 | 447 | |||
| 6 | Positif | 31 | 119 | 296 | 1.140 |
| Negatif | 57 | 546 | |||
| Netral | 31 | 298 | |||
| 7 | Positif | 59 | 181 | 547 | 1.685 |
| Negatif | 74 | 695 | |||
| Netral | 48 | 443 |
| Skenario | Sentimen | Yake | Total Yake | FastText | Total FastText |
|---|---|---|---|---|---|
| 1 | Positif | 64 | 186 | 601 | 1.748 |
| Negatif | 75 | 706 | |||
| Netral | 47 | 441 | |||
| 2 | Positif | 63 | 185 | 592 | 1.741 |
| Negatif | 75 | 706 | |||
| Netral | 47 | 443 | |||
| 3 | Positif | 34 | 121 | 320 | 1.153 |
| Negatif | 57 | 540 | |||
| Netral | 30 | 293 | |||
| 4 | Positif | 58 | 183 | 538 | 1.710 |
| Negatif | 77 | 724 | |||
| Netral | 48 | 448 | |||
| 5 | Positif | 64 | 186 | 311 | 1.144 |
| Negatif | 75 | 550 | |||
| Netral | 47 | 283 | |||
| 6 | Positif | 33 | 120 | 311 | 1.144 |
| Negatif | 58 | 550 | |||
| Netral | 29 | 283 | |||
| 7 | Positif | 58 | 182 | 534 | 1.692 |
| Negatif | 78 | 724 | |||
| Netral | 46 | 434 |
Pada Tabel 5.11 dan 5.12 dijabarkan jumlah hasil ektraksi dan ekspansi dengan skenario threshold 0 pada dataset A dan B. Pada skenario praproses 3 dan 6, duplikasi kata kunci yang muncul cenderung lebih banyak di antara praproses lainnya. Hal ini mengakibatkan terms yang dihasilkan cenderung lebih sedikit.
Evaluasi terhadap skenario pengujian 1 (Yake & FastText range bobot -1 dan 1) pada dataset A ditampilkan pada Tabel 5.13.
| Skenario | -1 (Threshold 0) | 0 (Threshold 0) | 1 (Threshold 0) | Akurasi | -1 (Threshold -3 s.d 3) | 0 (Threshold -3 s.d 3) | 1 (Threshold -3 s.d 3) | Akurasi |
|---|---|---|---|---|---|---|---|---|
| 1 | 0,37 | 0,47 | 0,33 | 0,4 | 0,02 | 0,63 | 0,05 | 0,46 |
| 2 | 0,52 | 0,14 | 0,28 | 0,36 | 0,02 | 0,63 | 0,04 | 0,46 |
| 3 | 0,52 | 0,13 | 0,31 | 0,36 | 0,01 | 0,63 | 0,03 | 0,46 |
| 4 | 0,52 | 0,14 | 0,27 | 0,36 | 0,01 | 0,63 | 0,06 | 0,46 |
| 5 | 0,5 | 0,28 | 0,29 | 0,39 | 0,02 | 0,63 | 0,05 | 0,46 |
| 6 | 0,3 | 0,54 | 0,34 | 0,43 | 0,02 | 0,63 | 0,03 | 0,46 |
| 7 | 0,29 | 0,51 | 0,26 | 0,39 | 0,01 | 0,63 | 0,06 | 0,46 |
Data yang disajikan pada Tabel 5.13 menunjukkan bahwa akurasi saja tidak bisa menjadi tolak ukur suatu skenario dikatakan baik dalam memprediksi sentimen. Dapat dilihat bahwa pada threshold -3 s.d 3 F-1 score yang dihasilkan pada prediksi -1, 0, dan 1, berturut-turut, adalah 0,02, 0,63, dan 0,05. Ini menunjukkan perbedaan yang signifikan terhadap threshold 0, di mana prediksi -1, 0,, dan 1, berturut-turut, adalah 0,37, 0,47, dan 0,33. Pada threshold -3 s.d 3 prediksi senitmen yang benar cenderung tidak seimbang jika dibandingkan dengan threshold 0. Data F-1 score yang ditunjukkan membuktikan bahwa dengan threshold tinggi maka sebagian besar prediksi akan jatuh pada sentimen netral. Threshold -3 s.d 3 tidak selaras dengan skenario pengujian 1, di mana bobot ekstraksi dan ekspansi hanya berkisar antara -1 dan 1 (Yake dan FastText). Oleh karena itu F-1 Score pada threshold netral -3 s.d 3 pada pengujian 1 sangat baik dalam memprediksi sentimen netral, tetapi sangat buruk dalam memprediksi sentimen negatif dan positif.
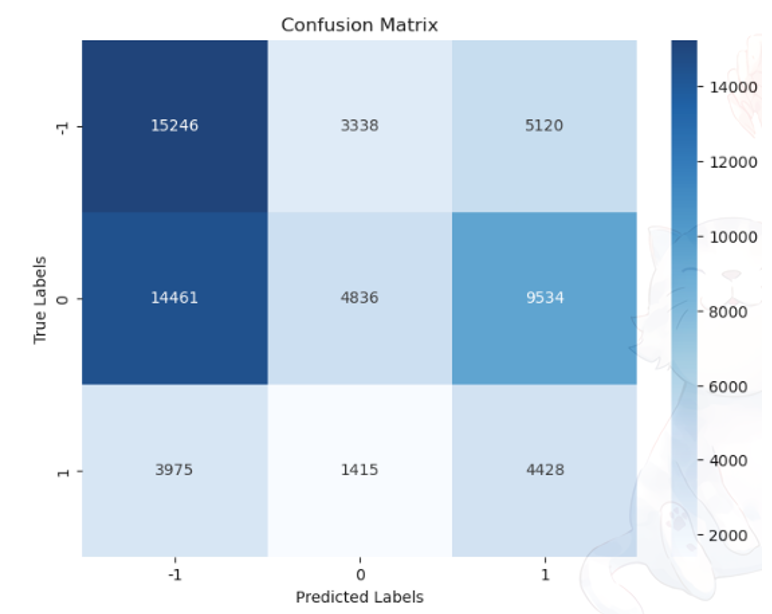
Selain itu, performa pada masing-masing skenario berkaitan dengan jumlah sentimen positif, netral, dan negatif pada Yake, FastText, dan InSet. Gambar di atas menunjukkan confusion matrix pada dataset A skenario praproses 1, prediksi 1, dan threshold 0 dengan jumlah sentimen positif, negatif, dan netral, berturut-turut, adalah 552, 719, dan 448 (Tabel 5.11). Hasil dari confusion matrix akan memiliki kecenderungan memprediksi sentimen negatif. Ini disebabkan karena terms yang dihasilkan pada proses Yake dan FastText lebih banyak terms dengan sentimen negatif.
Sebagai perbandingan, disajikan pula Gambar di bawah berupa confusion matrix pada dataset A, praproses 1, prediksi 1, dan threshold -3 s.d 3. Meskipun jumlah sentimen yang dihasilkan Yake dan FastText sama seperti threshold 0 pada Gambar di bawah, tetapi pada threshold -3 s.d 3, confusion matrix yang dihasilkan akan cenderung berpusat pada sentimen netral. Jatuhnya sebagian besar prediksi pada sentimen netral disebabkan karena penggunaan threshold -3 s.d 3.
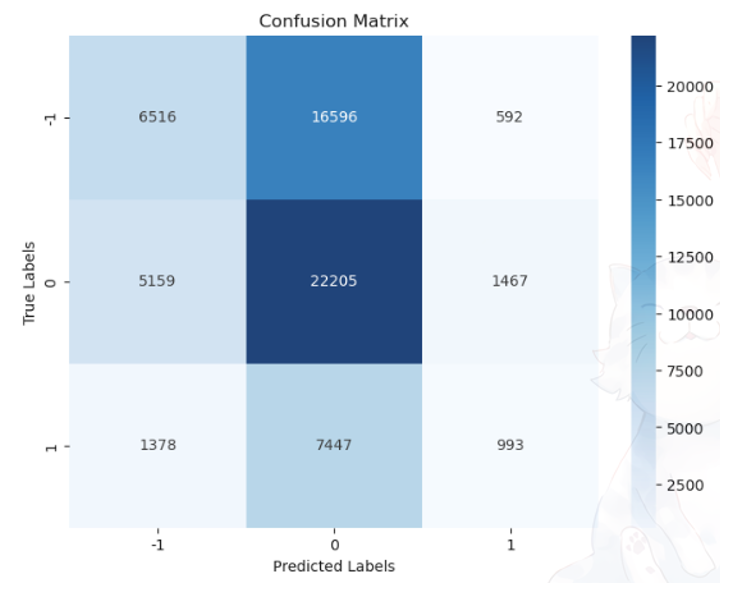
Kesimpulan
Kesimpulan yang didapat setelah melaksanakan beberapa skenario ektraksi kata kunci Yake, ekspansi kueri FastText, dan kamus Inset adalah sebagai berikut:
- Ekstraksi kata kunci dan ekspansi kueri dapat meningkatkan dan mengurangi nilai akurasi sentimen dan F1-Score. Berdasarkan penelitian ini, hal ini bergantung terhadap dua faktor, yakni:
- Threshold netral yang digunakan: Pada penelitian ini normalnya hasil kata kunci Yake dan ekspansi kueri FastText yang dihasilkan memiliki bobot 1 (positif) atau -1 (negatif), dengan tersebut threshold yang pantas digunakan adalah 0. Hal ini disebabkan karena bobot yang digunakan pada hasil kueri relatif kecil, maka threshold yang digunakan sebaiknya memiliki range yang kecil.
- Banyaknya kueri yang dihasilkan: Pada penelitian ini banyaknya kueri sangat berpengaruh terhadap hasil sentimen. Seandainya hasil kueri yang dihasilkan lebih banyak terhadap sentimen negatif, maka prediksi sentimen yang dihasilkan akan cenderung memprediksi sentimen negatif. Pada penggunaan Yake dan atau FastText, dengan juga mempertimbangkan F-1 Score, didapatkan skenario terbaik pada dataset A dan dataset B, berturut-turut adalah, 0,44 (menggunakan FastText saja, threshold netral 0) dan 0,43 (menggunakan Yake saja, threshold netral 0).
- Penggunaan kamus InSet dapat meningkatkan dan menurunkan akurasi sentimen. Hal ini bergantung terhadap threshold netral dan banyaknya sentimen pada kamus InSet.
Thershold netral yang pantas digunakan pada percobaan kamus InSet adalah -2 s.d 2 atau -3 s.d 3, sebab bobot pada kamus InSet cenderung relatif besar yakni -5 s.d 5. Perlu diketahui juga bahwa pada kamus InSet memiliki kueri sentimen negatif 2x lebih banyak dibandingkan sentimen positif. Maka dengan menggunakan kamus InSet dapat dipastikan bahwa kecenderungan data prediksi akan berada pada sentimen negatif.
Pada penggunaan InSet, dengan juga mempertimbangkan F-1 Score, didapatkan skenario terbaik pada dataset A dan dataset B, berturut-turut adalah, 0,47 (menggunakan InSet, Yake, dan FastText, threshold netral -2 s.d. 2) dan 0,45 (menggunakan InSet, Yake, dan FastText, threshold netral -2 s.d. 2).
Saran
Saran untuk penggunaan ekstraksi kata kunci dan ekspansi kueri sebagai analisis sentimen:
- Mempertimbangkan penggunaan skenario uji coba parameter model ekstraksi kata kunci Yake dan ekspansi kueri FastText.
- Mempertimbangkan penggunakan nilai threshold netral yang sesuai dengan bobot yang digunakan.
- Mempertimbangkan penggunakaan skenario menggunakan kamus lexicon lain, selain InSet. Sebab kamus InSet memiliki sentimen negatif 2x lebih banyak daripada sentimen positif.
Daftar Pustaka
Amien, M. (2023). Sejarah dan Perkembangan Teknik Natural Language Processing (NLP) Bahasa Indonesia. TINJAUAN TENTANG SEJARAH, PERKEMBANGAN TEKNOLOGI, DAN APLIKASI NLP DALAM BAHASA INDONESIA. Jurnal Mediapsi.
Annur, Cindy Mutia. (2023). Jumlah Pengguna Twitter di Indonesia Capai 14,75 Juta per April 2023, Peringkat Keenam Dunia. https://databoks.katadata.co.id/datapublish/2023/05/31/jumlah-pengguna-twitter-di-indonesia-capai-1475-juta-per-april-2023-peringkat-keenam-dunia
CHHOEUN, Tola. (2023, Maret 14). What are some common challenges or pitfalls of lexicon-based sentiment analysis. Linkedin. https://www.linkedin.com/advice/1/what-some-common-challenges-pitfalls-lexicon-based.
Fasttext. (2022). Word Vectors for 157 Languages. https://fasttext.cc/docs/en/crawl-vectors.html
Fasttext. (2022). FastText Library for Efficient Text Classification and Representation Learning. https://fasttext.cc/
Fasttext. (2022). Word Representations. https://fasttext.cc/docs/en/unsupervised-tutorial.html
Flores, Veronica & Jasa, Lie & Linawati, Linawati. (2020). Analisis Sentimen untuk Mengetahui Kelemahan dan Kelebihan Pesaing Bisnis Rumah Makan Berdasarkan Komentar Positif dan Negatif di Instagram. Majalah Ilmiah Teknologi Elektro. 19. 49. 10.24843/MITE.2020.v19i01.P07.
INESCTEC. (2023). YAKE!. https://www.inesctec.pt/en/technologies/yake#
Koto, Fajri & Rahmaningtyas, Gemala. (2017). InSet Lexicon: Evaluation of a Word List for Indonesian Sentiment Analysis in Microblogs. 10.1109/IALP.2017.8300625.
LIAAD. (2018). Yet Another Keyword Extractor (YAKE). https://liaad.github.io/yake/
Prakash, T. N., & Aloysius, A. (2021). Lexicon Based Sentiment Analysis (LBSA) to Improve the Accuracy of Acronyms, Emoticons, and Contextual Words. Society of Statistics, Computer and Applications,(Accepted-Forthcoming).
Turing. How Does Natural Language Processing Function in AI?. https://www.turing.com/kb/natural-language-processing-function-in-ai
Xhymshiti, Meriton. (2020). Domain independence of Machine Learning and lexicon based methods in sentiment analysis. https://essay.utwente.nl/81995/