- Published
Deteksi Ketidakselarasan Undang-undang Republik Indonesia
- Published
- Surya Abdillah, Davian Benito, dan Gaudhiwaa Hendrasto
Penambahan dan perubahan peraturan perundang-undangan selalu terjadi setiap waktu dan dapat mengakibatkan terjadinya disharmonisasi (ketidakselarasan) yang akan mengakibatkan kebingungan dalam masyarakat untuk memilih dasar dalam bertindak. Di sisi lain perkembangan Artificial Intelligence, salah satunya Natural Language Processing dapat menjadi pendekatan solusi dalam permasalahan ini dan diharapkan dapat meningkatkan efisiensi dan efektivitas pemeriksaan ketidakselarasan. Data berupa 110 dokumen dilakukan ekstraksi informasi, termasuk pasal dan ayat. Hasil ekstraksi kemudian dilakukan praproses data berupa case folding, remove links, spell checker, stemming, dan remove stopwords. Data yang telah bersih dilakukan topic modeling menggunakan BERTopic dan cosine similarity dengan nilai threshold 0,75. Pasangan ayat dalam cluster yang sama dan melewati ambang batas kemudian akan dilakukan deteksi ketidakselarasan menggunakan model mDeBERTa. Dalam pemenuhan data training digunakan ChatGPT untuk mendapatkan data pasangan ayat yang selaras dan tidak selaras. Berdasarkan hasil pengujian performa terbaik dihasilkan dengan nilai akurasi 93,07%, precision 99,43%, recall 86,57%, dan F1 score 92,55% pada model mDeBERTa dengan parameter learning rate 2e-5 dan batch size 8 dengan menggunakan penambahan data peraturan perundang-undangan.
Kata kunci: deteksi ketidakselarasan, peraturan perundang-undangan, BERTopic, mDeBERTa, cosine similarity
Daftar Isi
- Latar Belakang
- Rumusan Masalah
- Tujuan
- Manfaat
- Metodologi
- Dataset
- Pengolahan Data
- Ekstraksi Data
- Data Preprocessing
- Topic Modelling
- Cosine Similarity
- Pembentukan Model
- Pretrained Model
- Finetune Model Pertama
- Generate Data Baru dengan ChatGPT
- Finetune Model Kedua
- Uji Coba Model
- Pembahasan
- Hasil Uji Coba Skenario Penggunaan Cosine Similarity
- Hasil Uji Coba Skenario Variasi Dataset
- Hasil Uji Coba Skenario Hyperparameter Tuning Model
- Hasil Prediksi ke Semua Dokumen
- Penjelasan Hasil Prediksi
- Kesimpulan
- Saran
- Referensi
Latar Belakang
Berdasarkan Pasal 1 ayat (3) Undang-Undang Dasar 1945, negara Indonesia merupakan negara hukum. Hal ini dapat dimaknai bahwa segala tindakan yang dilakukan oleh seluruh masyarakat wajib didasari atas hukum yang berlaku. Peraturan perundang-undangan sebagai salah satu norma hukum tertulis merupakan salah satu dasar hukum yang dimaksud. Dalam perkembangannya peraturan-peraturan ini selalu bertambah dan banyak diantaranya dilakukan perubahan. Terhitung hingga 18 Agustus 2022, Indonesia telah memiliki 42.161 peraturan dimana angka ini masih belum termasuk peraturan yang dikeluarkan oleh kepala daerah secara langsung (Bayu, 2022).
Namun, seiring berjalannya waktu dan bertambahnya perundang-undangan yang berlaku, muncul permasalahan dalam menjaga harmonisasi antar perundang-undangan yang dibuat. Disharmonisasi/ketidakselarasan dalam peraturan perundang-undangan dapat diakibatkan oleh perbedaan waktu dan lembaga pembentuk peraturan, adanya pergantian pejabat pembentuk, dan lemahnya koordinasi dalam proses pembentukan. Ketidakselarasan ini dapat menimbulkan berbagai permasalahan serius dalam jalannya pemerintahan, seperti perbedaan penafsiran dalam pelaksanaan peraturan, terjadinya ketidakpastian hukum, pelaksanaan peraturan menjadi tidak efisien dan efektif, dan terjadinya disfungsi hukum (Mahendra, 2010). Salah satu bentuk dari ketidakselarasan antar ayat adalah kondisi suatu ayat merupakan kalimat kontradiksi ayat lainnya.
Wasis Susetio dalam penelitiannya telah melakukan penelitian terhadap disharmonisasi yang terjadi dalam peraturan perundang-undangan terkait agraria. Salah satu poin disharmonisasi yang disebutkan adalah status dari hutan, dimana disebutkan “hutan yang berada pada tanah yang tidak dibebani dengan hak atas tanah”, sedangkan dalam UUPA, tanah yang tidak dibebani atas hak atas tanah merupakan tanah negara (Susetio, 2013).Terjadi kesulitan apabila ingin melakukan perbaikan dikarenakan setiap sektor berdasar pada Peraturan Perundang-Undangan sektoral masing-masing dan memiliki derajat yang sama. Sehingga, langkah penanganan disharmonisasi perlu dilakukan sedari awal pembentukan peraturan guna menghindari kesulitan ini.
Solusi yang saat ini dilakukan untuk menghadapi masalah ketidakselarasan peraturan adalah dengan melakukan judicial review PUU terhadap UUD 1945 oleh Mahkamah Konstitusi atau pengujian PUU dibawah PUU terhadap PUU oleh Mahkamah Agung (Wahyuni, 2023). Proses pengecekan ini masih dilakukan secara manual. Hal ini menyebabkan ketidakefektifan dan ketidakefisienan dalam proses tersebut karena akan memiliki tingkat probabilitas human error yang lebih tinggi dan membutuhkan waktu lama untuk setiap kali dikeluarkannya peraturan perundang-undangan baru. Sebagai contoh, perubahan Undang-Undang Nomor 13 Tahun 2003 tentang Ketenagakerjaan atas gugatan Serikat Pekerja PLN memakan waktu hampir 10 bulan (terhitung dari sidang pertama hingga keputusan, 22 Februari s.d. 13 Desember 2017) (TV, 2022)
Oleh karena itu, digitalisasi memiliki peranan yang sangat penting dalam memperbaiki sistem dari proses yang telah ada. Artificial intelligence (AI) sebagai salah satu pendekatan yang digunakan dalam digitalisasi telah banyak diimplementasikan dan terbukti dapat menyelesaikan permasalahan yang ada. Penerapan AI dalam penyelesaian permasalahan memungkinkan masalah tersebut diselesaikan secara efektif dan efisien karena proses automasi yang dilakukan oleh komputer dan dengan tingkat akurasi yang tinggi. Dari dasar tersebut, penelitian ini mengusulkan penerapan AI dalam menyelesaikan permasalahan ketidakselarasan peraturan perundang-undangan negara.
Salah satu bentuk penerapan AI adalah pendekatan unsupervised learning pada kalimat inkonsisten, yakni metode K-Means telah dilakukan untuk menyelesaikan permasalahan prediksi kontradiksi. Hasil pengujian menunjukkan bahwa metode K-Means memiliki performa yang baik dalam mendeteksi dataset yang berisi kalimat redundan atau inkonsisten secara keseluruhan. Namun, performa metode ini menurun secara signifikan apabila diterapkan pada data dengan kondisi tidak sepenuhnya redundan atau konsisten. Sehingga, diperlukan penanganan lanjutan dalam menangani data karakteristik tersebut (Florence Sedes, 2018).
Pendekatan supervised learning, SVM dan KNN juga telah dilakukan dalam prediksi inkonsistensi pada artefak keamanan. Penelitian oleh Xuni Huang, menunjukkan peningkatan akurasi model ketika menggunakan fitur similaritas dan word vectors. Selain itu, dalam penelitian telah digunakan seleksi nilai similaritas sebagai salah satu bagian prediksi untuk label inkonsisten (X, 2021).
Selain itu, penelitian terdahulu telah menyusun dataset kalimat kontradiksi dan mengembangkan model prediksi berbasis semantik dimana didapati model masih mengalami kesulitan dalam menangani kasus reasoning, komparatif, dan superlatif dalam hal numerikal (Fahrurrozi Rahman, 2021). Meski demikian, pembuatan model serupa masih relevan dengan permasalahan peraturan perundang-undangan karena model bahasa peraturan yang pada umumnya selalu melakukan pengejaan terhadap angka.
Penelitian lain menunjukkan bahwa penggunaan dataset dalam proses training model dapat sangat mempengaruhi performa model (Laban, 2022). Sehingga, diperlukan dataset yang berkesesuaian dengan task yang ingin dilakukan agar performa model dapat meningkat. Augmentasi data untuk data training juga mempengaruhi performa model menjadi lebih baik (Nafide Sadat Moosavi, 2022). Penggunaan dataset IndoNLI merupakan salah satu pendekatan yang dapat dilakukan untuk menyesuaikan model, yakni menggunakan bahasa Indonesia. Namun, bahasa dalam peraturan memiliki karakteristik yang baku dan berbeda dengan gaya bahasa pada umumnya Oleh sebab itu, diperlukan augmentasi data kalimat tidak selaras dan selaras dari peraturan perundang-undangan guna mendapatkan model dengan performa terbaik.
Berdasarkan deskripsi diatas, diusulkan sebuah sistem untuk mendeteksi ketidakselarasan peraturan perundang-undangan dengan menerapkan metode topic modeling (BERTopic), thresholding cosine similarity, dan mDeBERTa dengan pemberian augmentasi data kalimat peraturan yang selaras dan tidak selaras. Beberapa skenario pengujian dilakukan untuk mendapatkan model dengan performa terbaik.
Rumusan Masalah
Berikut rumusan masalah yang dihadapi dalam penelitian ini:
Bagaimana persiapan data peraturan perundang-undangan agar dapat dilakukan proses topic modeling dan deteksi ketidakselarasan antar pasangan ayat?
Bagaimana melakukan proses topic modeling pada data peraturan perundang-undangan?
Bagaimana mendeteksi ketidakselarasan antar pasangan ayat?
Bagaimana melakukan evaluasi model deteksi ketidakselarasan antar pasangan ayat?
Tujuan
Tujuan dilakukannya penelitian ini adalah untuk mengembangkan penerapan AI dalam deteksi ketidakselarasan antar ayat dalam perundang-undangan negara. Model AI yang dibuat berupa model NLP yang dapat menganalisis relasi semantik antar ayat untuk menentukan apakah terdapat ketidakselarasan dalam pasangan ayat tersebut.
Manfaat
Penelitian ini diharapkan dapat bermanfaat bagi berbagai pihak yang terlibat, yaitu:
- Mahkamah Agung dan Mahkamah Konstitusi
- Mendapatkan pertimbangan terkait peraturan yang dilakukan judicial review dan pengujian perundang-undangan.
- Lembaga penyusun peraturan perundang-undangan
- Lembaga penyusun peraturan dapat menghasilkan peraturan perundang-undangan negara yang berkualitas dengan memastikan tidak ada pasangan ayat yang tidak selaras dengan ayat lainnya, baik dalam satu dokumen yang sama maupun berbeda.
- Terciptanya sistem yang lebih efisien dengan mengurangi keperluan perubahan peraturan perundang-undangan yang ada.
- Masyarakat
- Masyarakat bisa mendapatkan keadilan dalam proses hukum negara karena perundang-undangan yang konsisten dan jelas sehingga tidak menimbulkan celah untuk ketidakadilan.
- Adanya kejelasan akan dasar hukum dalam mengambil setiap tindakan
- Keputusan peradilan
- Proses hukum peradilan dapat berjalan dengan adil tanpa menimbulkan kebingungan dengan terciptanya kesamaan penafsiran dan tidak adanya penggunaan peraturan yang berkontradiksi terkait perkara yang diadili.
- Proses hukum peradilan dapat berjalan dengan lancar dan efisien karena perundang-undangan yang konsisten dan jelas
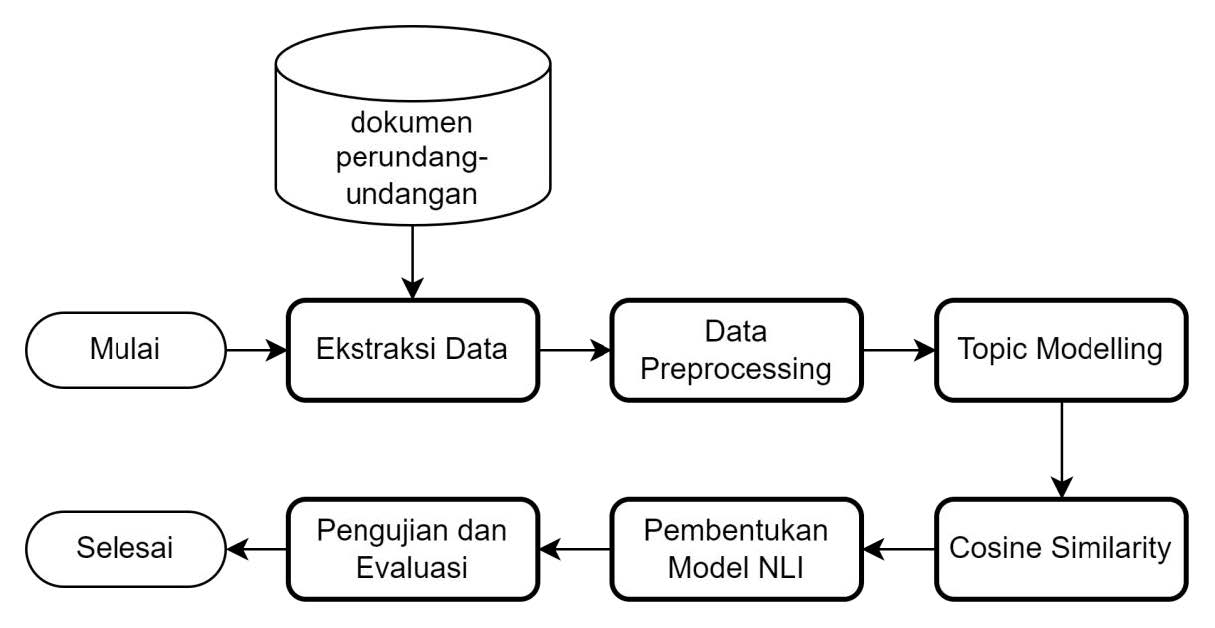
Metodologi
Untuk mencapai tujuan sebagaimana disebutkan sebelumnya, maka disusunlah rangkaian proses penelitian pada Gambar di bawah.
Dataset
Data yang digunakan dalam penelitian ini berupa 110 data dokumen (pdf dan docx) peraturan perundang-undangan negara mengenai investasi dengan jenis, tahun, dan tingkatan yang beragam. Terdapat tiga asas dalam penyelesaian pertentangan antar peraturan perundang-undangan, yakni asas lex superior derogat legi inferiori (peraturan tingkatan lebih tinggi mengesampingkan yang lebih rendah), lex specialis derogat legi generali (peraturan lebih khusus mengesampingkan yang lebih umum) dan asas lex posterior derogat legi priori (peraturan baru mengesampingkan yang lama) (Budianto, 2022).Berdasarkan Pasal 7 ayat (1) Undang-Undang Nomor 12 Tahun 2011 tentang Pembentukan Peraturan Perundang-undangan, Tingkatan peraturan dalam dataset ini adalah berikut:
- Undang-Undang
- Peraturan Pemerintah Pengganti Undang-Undang
- Peraturan Pemerintah
- Peraturan dan Keputusan Presiden
- Peraturan dan Keputusan Menteri
Datasetnya tersedia di: Google Drive
Pengolahan Data
Data dokumen yang ada selanjutnya dilakukan pengolahan, baik dari ekstraksi fitur yang diperlukan, data preprocessing, topic modeling, cosine similarity, dan pendeteksian ketidakselarasan dalam pasangan ayat.
Ekstraksi Data
Dataset dokumen peraturan perundang-undangan kemudian dilakukan ekstraksi untuk mendapatkan informasi jenis, nomor, tahun, perihal, nomor pasal, nomor ayat, dan bunyi ayat dari setiap dokumen. Ekstraksi ini dilakukan menggunakan program yang dapat dilakukan parsing dokumen berdasarkan pola struktur kalimat dalam dokumen. Adapun dokumen yang terdapat pada dataset, terdiri atas tipe diktum dan tipe pasal. Pseudocode di bawah merupakan algoritma parsing dokumen bertipe pasal.
FUNCTION parse_document_pasal(document_path)
OPEN document_path
READ text from the file
CONVERT text to lowercase
INITIALIZE data dictionary with keys: 'pasal', 'ayat', 'teks'
INITIALIZE df DataFrame with data dictionary
INITIALIZE pasal_teks_list as an empty list
SPLIT text into pasal_texts using pasal_pattern
FOR each pasal in pasal_texts starting from the second element
IF 'cukup jelas.' is in pasal
BREAK from the loop
ENDIF
APPEND pasal to pasal_teks_list
SPLIT pasal into ayat_texts using ayat_pattern
FOR each ayat in ayat_texts
ADD a new row to the DataFrame df with corresponding pasal number, ayat number, and the stripped ayat as the text
ENDFOR
ENDFOR
RETURN df, pasal_teks_list, the document name from the path, and whether the length of pasal_teks_list is greater than 2
ENDFUNCTION
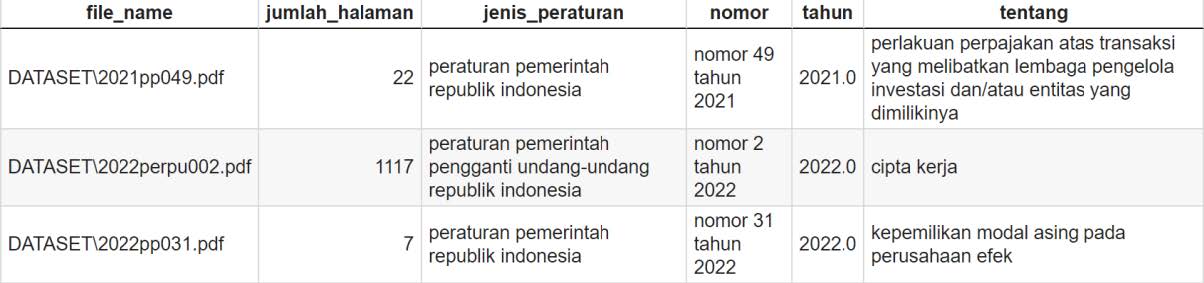
Hasil ekstraksi yang didapatkan kemudian dimasukkan ke dalam data frame dengan kolom fitur terdiri dari nama dokumen, jumlah halaman, jenis peraturan, nomor, tahun, nomor pasal, nomor ayat, perihal, dan bunyi ayat. Contoh data frame dari hasil ekstraksi dapat dilihat pada Gambar di bawah.

Data Preprocessing
Setelah didapatkan data ayat untuk setiap dokumen, dilakukan tahap preprocessing text yang terdiri dari :
Lower-Case
Mengubah semua data teks menjadi huruf kecil untuk memastikan kesamaan dan konsistensi kapitalisasi teks. Hal ini dilakukan agar perbedaan penulisan kapital dari sebuah kata tidak dianggap berbeda, sehingga dapat mengurangi dimensi fitur kosa kata.
(1) subbagian persuratan mempunyai tugas melaku kan urusan umum, penyiapan surat menyurat,
penggandaan, pencelakan, dan kearsipan.
- Remove Links
Dokumen peraturan perundang-undangan terkadang mengandung link yang tanpa sengaja terbawa pada saat ekstraksi ayat. Link tersebut bukan termasuk bagian dari ayat dan tidak relevan terhadap permasalahan sehingga perlu dihapus dari data.
(1) subbagian persuratan mempunyai tugas melaku kan urusan umum, penyiapan surat menyurat,
penggandaan, pencelakan, dan kearsipan.
- Spell Checker
Hasil ekstraksi ayat dari dokumen peraturan perundang-undangan terkadang terdapat ejaan kata yang tidak benar sehingga perlu dilakukan spell checker untuk membenarkan dan memastikan ejaan semua kata dalam ayat sudah benar. Hal ini diperlukan untuk memastikan makna dari kata yang benar yang didapatkan oleh model.
(1) subbagian persuratan mempunyai tugas mengurus kan urusan umum, penyiapan surat menyurat,
penggandaan, pencelakan, dan kearsipan.
- Stemming
Mengubah semua kata menjadi bentuk dasarnya. Hal ini dilakukan untuk mengurangi variasi morfologis dari kata sehingga makna dasarnya saja yang didapatkan. Sering kali makna dasar dari kata-kata dalam suatu kalimat sudah dapat merepresentasikan keseluruhan kalimat.
(1) subbagian surat punya tugas urus kan urus umum, siap surat surat, ganda, cela, dan arsip.
- Remove Stopwords
Menghapus kata-kata umum dalam kalimat yang memiliki nilai informatif yang kecil. Kata-kata umum tersebut dapat dianggap tidak relevan dalam membantu proses analisis dan malah menimbulkan noise yang tidak diinginkan dalam analisis teks.
(1) subbagian surat tugas urus urus umum, surat surat, ganda, cela, arsip.
Topic Modelling
Data ayat yang didapatkan kemudian perlu dipasangkan dengan ayat yang lain untuk kemudian dilakukan pengecekan ketidakselarasan antar pasangan ayat tersebut. Jumlah ayat hasil ekstraksi untuk semua dataset dokumen adalah 11.144 ayat. Pemasangan antar ayat pada seluruh data ayat, akan menghasilkan jumlah data pasangan ayat yang sangat banyak, yakni 6.368.796 pasangan ayat. Terdapat dua permasalahan yang muncul dari hal tersebut, yang pertama pendekatan ini tidak scalable karena apabila dilakukan penambahan dataset baru, kompleksitas waktu dari prediksi model akan bertambah 2 kali lipat. Kedua, data pasangan ayat akan memiliki konteks pembahasan yang terlalu berbeda, sehingga bisa mengurangi performa model.
Untuk mengatasi permasalahan tersebut, dilakukan topic modeling untuk setiap dokumen. Tujuan dari topic modeling adalah untuk mengelompokkan dokumen yang memiliki tingkat topic similarity yang tinggi. Dokumen yang berada dalam cluster yang sama dapat dianggap memiliki sub topik bahasan yang mirip sehingga pengecekan ketidakselarasan antar ayat dari setiap dokumen dapat tereduksi menjadi sejumlah pasangan ayat antar dokumen dalam cluster yang sama saja.
Topic modeling yang dilakukan dalam penelitian ini menggunakan model BERTopic. Model ini berbasis arsitektur transformer model BERT (Bidirectional Encoder Representations from Transformers) untuk mendapatkan representasi kata-kata dari teks, yang kemudian digunakan untuk mengelompokkan dokumen ke dalam cluster topik masing-masing. Hasil clustering BERTopic pada dataset peraturan perundang-undangan yang digunakan pada penelitian ini dapat dilihat pada Gambar di bawah.
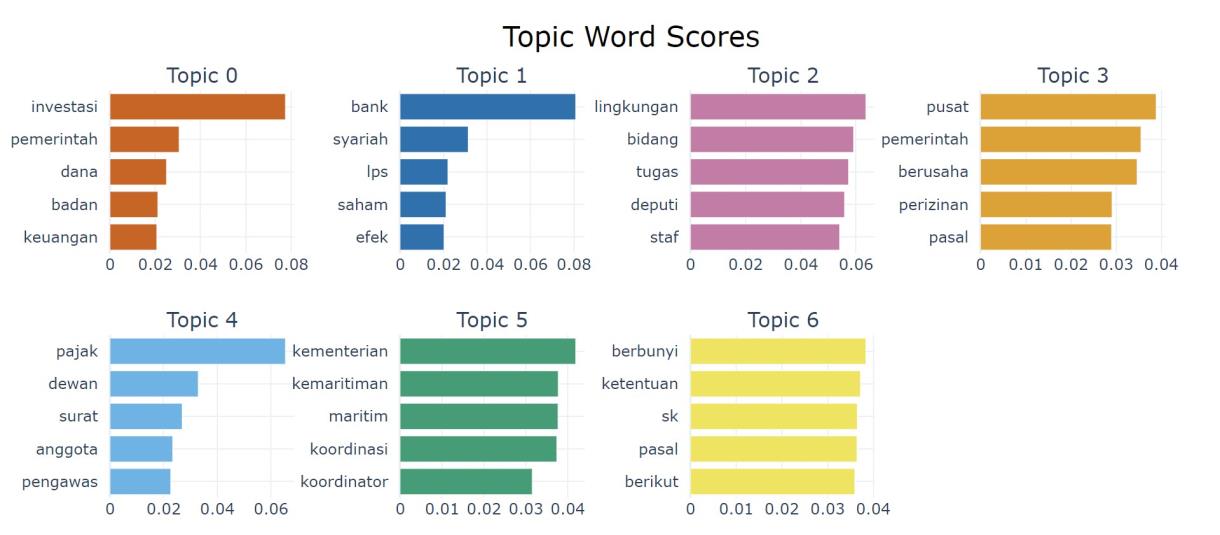
Adapun, total clustering BERTopic pada dataset perundang-undangan ini mencapai 47 topik, dengan persebaran clustering topik secara lengkap terdapat pada dokumen terlampir. Terlihat pada ‘Topic 0’ mengandung kata investasi, pemerintah, dana, badan, dan keuangan, yang mengindikasikan topik ini secara garis besar membahas tentang “Regulasi Pemerintah dalam Mengelola Investasi, Dana, dan Keuangan Badan Usaha”. Di sisi lain pada ‘Topic 1’, membicarakan “Peran Bank Konvensional dan Syariah, serta LPS dalam mengatur Saham dan Efek keuangan”, dengan adanya kata-kata seperti bank, syariah, LPS, saham, dan efek yang mengisyaratkan garis besar topik ini.
Dengan adanya clustering BERTopic, maka didapatkan kumpulan ayat yang membahas topik atau bahasan yang sama. Selanjutnya, agar didapatkan pasangan ayat yang semakin similar (pembahasan semakin spesifik), maka digunakan metode cosine similarity pada tahap selanjutnya.

Cosine Similarity
Perhitungan cosine similarity digunakan untuk menghitung kesamaan struktur pada setiap pasangan ayat dalam cluster topik yang sama. Tujuan dilakukannya perhitungan cosine similarity adalah untuk memberikan tambahan kriteria terhadap pasangan ayat (dalam mendapatkan pasangan ayat yang cukup similar) yang akan masuk ke dalam model. Cosine similarity dalam penelitian ini menggunakan tokenizer dari pretrained model indobert yang telah di-train menggunakan corpus bahasa Indonesia yang besar. Hasil dari tokenizer ini berupa representasi token untuk setiap kata, dimana setiap token direpresentasikan sebagai vektor di dalam ruang vektor. Adapun perhitungan cosine similarity didapatkan pada Persamaan 3.1.
Cosine similarity dilakukan dengan mengukur sejauh mana dua vektor memiliki arah yang sama dalam ruang vektor. Hal ini melibatkan perkalian titik vektor (A · B), serta perhitungan panjang dari masing-masing vektor ||A|| dan ||B||. Hasil cosine similarity berada dalam rentang -1 hingga 1, di mana nilai 1 menunjukkan arah yang sama (similar) dan nilai -1 menunjukkan arah yang berlawanan (tidak similar). Contoh dari kombinasi pasangan ayat yang memiliki nilai similarity tinggi hingga nilai similarity rendah direpresentasikan pada Tabel di bawah.
| Teks 1 | Teks 2 | Similarity |
|---|---|---|
| perusahaan industri yang tidak memenuhi ketentuan sebagaimana dimaksud dalam pasal 7 ayat (1) atau perusahaan industri yang tidak memiliki izin perluasan sebagaimana dimaksud dalam pasal 24 ayat (1) dikenal sanksi administratif berupa: a. peringatan tertulis; b. denda administratif; c.penutupan sementara; d.pembekuan iui; dan/atau e. pencabutan iui | perusahaan industri yang tidak memiliki iui sebagaimana dimaksud dalam pasal 2 ayat (1) dikenal sanksi administratif berupa: a. peringatan tertulis; b. denda administratif; dan c. penutupan sementara. | 0,9118 |
| (1) menteri, gubernur, dan bupati/walikota sesuai dengan kewenangannya mengenakan sanksi administratif sebagaimana dimaksud dalam pasal 30 kepada perusahaan industri. | pembayaran denda administratif sebagaimana dimaksud pada ayat (1) dilakukan paling lama 30 (tiga puluh) hari sejak surat pengenaan denda administratif diterima. | 0,7559 |
| pembayaran denda administratif sebagaimana dimaksud pada ayat (1) dilakukan paling lama 30 (tiga puluh) hari sejak surat pengenaan denda administratif diterima. | dalam rangka pendalaman struktur dan peningkatan daya saing industri, kepala instansi pemerintah yang menyelenggarakan pelayanan terpadu satu pintu dalam menerbitkan iui mengacu pada kebijakan penanaman modal bidang industri yang ditetapkan oleh menteri. bab iv tata cara pemberian iui bagian kesatu iui kecil | 0,4045 |
Sebelum pasangan ayat ini digunakan ke dalam model, digunakan threshold cosine similarity sebesar 0,75 untuk menyaring pasangan ayat yang cukup similar. Adapun perhitungan cosine similarity ini belum cukup untuk mendapatkan relasi semantik antar kalimat yang lebih kompleks, seperti relasi antar kalimat kontradiksi. Oleh karena itu, penggunaannya hanya sebatas untuk memastikan data pasangan ayat memiliki similaritas atau relevansi yang sama.
Pembentukan Model
Model yang dikembangkan berupa model Natural Language Inference (NLI) untuk menganalisis relasi semantic inference guna mendeteksi ketidakselarasan dari sepasang kalimat. Pengembangan model tersebut terdiri dari beberapa tahapan yaitu:
Pretrained Model
Dalam penelitian, arsitektur model mDeBERTa-v3-base digunakan. Model mDeBERTa (Decoding-enhanced BERT with disentangled attention), merupakan arsitektur model berbasis Transformer yang menggunakan improvisasi tingkatan pada layer BERT and RoBERTa, dengan menggunakan 2 teknik. Teknik pertama yaitu penggunaan mekanisme disentangled attention, untuk representasi dua vektor yang mengkodekan konten dan posisi masing-masing, dan attention weight antar kata-kata dihitung menggunakan matriks terpisah berdasarkan konten dan posisi relatifnya. Teknik kedua yaitu penggunaan dekoder masker yang dioptimasi untuk menggabungkan posisi absolut dalam lapisan decoding guna prediksi token tersembunyi.
Model dengan arsitektur ini dikembangkan oleh Microsoft dengan menggunakan dataset CC100 multilingual yang mengandung 100 bahasa. Penelitian ini menggunakan pretrained model berbasis arsitektur ini yang telah di fine tune pada dataset XNLI dan dataset multilingual-NLI-26lang-2mil7, dengan downstream task NLI dengan labelnya yaitu entailments, neutral, dan contradictions. Gabungan dari kedua dataset tersebut mengandung 2.7 juta pasangan kalimat, dalam 27 bahasa, salah satunya bahasa Indonesia (Weizhu Chen, P. H. J. H. (2023)).
Finetune Model Pertama
Pretrained model yang dipakai berupa model multilingual yang dapat menerima kalimat dalam berbagai bahasa. Untuk mendapatkan hasil yang lebih baik dengan menspesifikan ke permasalahan dalam penelitian ini, dilakukan tahap fine tune model terhadap dataset indoNLI, dataset SNLI, dan dataset MNLI yang lelah diterjemahkan ke dalam bahasa Indonesia, dengan total gabungan ketiga dataset tersebut mengandung 1 juta pasangan kalimat. Dataset ini berupa dataset general yang berisikan pasangan kalimat keseharian beserta label korespondensinya. Tujuan dari proses fine tune ini adalah menghasilkan model NLI yang dapat memahami relasi semantik dari kata-kata berbahasa Indonesia dengan lebih baik karena didukung oleh dataset NLI berbahasa Indonesia dengan jumlah yang sangat banyak.
Generate Data Baru dengan ChatGPT
Dataset NLI yang dipakai pada tahap proses fine tune sebelumnya, mengandung berbagai pasangan kalimat dengan struktur kalimat keseharian. Namun dalam permasalahan penelitian ini, pasangan kalimat yang akan digunakan berupa ayat dari pasal perundang-undangan negara. Struktur kalimat dari sebuah ayat perundang-undangan memiliki ciri unik yang membuatnya berbeda dari struktur kalimat keseharian. Contoh perbandingan antar kalimat ayat dan kalimat keseharian yang dipakai dalam dataset NLI sebelumnya dapat dilihat pada Tabel di bawah.
| Kalimat Ayat | Kalimat Dataset NLI |
|---|---|
| Tarif layanan Badan Layanan Umum Pusat Investasi Pemerintah pada Kementerian Keuangan merupakan imbalan atas jasa layanan pembiayaan ultra mikro dari Badan Layanan Umum Pusat Investasi Pemerintah pada Kementerian Keuangan kepada penyalur dan/ atau lembaga linkage. | Cukup memalukan, itu semua adalah kesulitan, kemalasan, ketidakberbentukan yang menyedihkan di masa muda, pasak bundar di lubang persegi, apa pun yang Anda inginkan? |
| Kerja sama dengan pihak ketiga sebagaimana dimaksud pada ayat (1) huruf c dilaksanakan dengan: a. memberikan atau menerima kuasa kelola; b. membentuk perusahaan patungan; atau c. bentuk kerja sama lainnya. | Kampanye tampaknya menjangkau kumpulan kontributor baru. |
| Pelaku Usaha adalah orang perseorangan atau badan usaha yang melakukan usaha dan/atau kegiatan pada bidang tertentu. | Dia bahkan belum pernah melihat gambar-gambar seperti itu sejak beberapa film bisu diputar di beberapa teater seni kecil. |
Oleh sebab perbedaan struktur kalimat tersebut, penggunaan data pasangan ayat sebagai dataset fine tune pada model dapat meningkatkan performa model dalam menangkap relasi semantik dari pasangan ayat perundang-undangan.
Pengumpulan data ayat perundang-undangan sebagai dataset fine tune model dilakukan dengan cara melakukan label manual antara 2 pasang ayat dalam cluster topik yang sama, dengan pilihan label ‘kontradiksi’ atau ‘selaras’. Dalam hal ini, pasangan ayat dikatakan ‘kontradiksi’, apabila salah satu kalimat membuat kalimat lainnya menjadi salah. Sedangkan pasangan ayat dikatakan ‘selaras’, apabila salah satu kalimat tidak membuat kalimat lainnya menjadi salah.
Namun muncul kendala imbalanced dataset dalam proses pengumpulan dataset ini, karena data pasangan ayat dari dokumen perundang-undangan yang didapatkan mayoritas memiliki hubungan ‘selaras’, yakni 4 data ‘tidak selaras’ dan ‘996’ ‘selaras’. Imbalance dataset dapat menyebabkan model menjadi bias terhadap data dengan label yang lebih banyak, sehingga membuat performa model berkurang. Oleh sebab itu, untuk mendapatkan pasangan ayat yang memiliki hubungan ‘kontradiksi’, digunakan bantuan ChatGPT untuk membuat data ayat sintetik yang berkontradiksi dengan ayat yang diberikan. Contoh dari prompt ChatGPT untuk mendapatkan ayat ‘kontradiksi’ sebagai berikut

Dari pembuatan data ayat tersebut, terkumpul dataset ayat dengan jumlah 1000 pasang ayat berlabel kontradiksi dan 1000 pasang ayat berlabel selaras. Dataset ini berupa dataset PUU yang berisikan pasangan ayat perundang-undangan beserta label korespondensinya.
Finetune Model Kedua
Model dilakukan fine tune lagi menggunakan dataset PUU yang telah dibuat. Total dari dataset tersebut berjumlah 2000 pasang ayat. Model yang telah di fine tune ini merupakan model akhir dari pengembangan model NLI untuk klasifikasi ayat perundang-undangan negara. Model nantinya akan mengklasifikasikan pasangan ayat ke dalam 2 kelas, yaitu ‘selaras’ dan ‘kontradiksi’.
Uji Coba Model
Metrik utama yang dipakai untuk menentukan performa model dalam penelitian ini menggunakan metrik akurasi yang dihitung berdasarkan jumlah prediksi data yang benar dibandingkan dengan jumlah keseluruhan data. Selain metrik akurasi, juga digunakan metrik nilai f1 score, recall, dan precision untuk mengecek performa model terhadap setiap label prediksinya. Perhitungan metrik tersebut mengikuti rumus sebagai berikut:
Model diujicobakan menggunakan dataset validasi dari dataset PUU, untuk mengecek performa generalisasi model pada data baru. Dilakukan juga beberapa skenario pengujian untuk menguji variasi pendekatan dari pengembangkan model yang dilakukan, yaitu sebagai berikut:
- Skenario pengujian berdasarkan penggunaan cosine similarity dengan nilai threshold 0,75 pada setiap topik
- Skenario pengujian berdasarkan variasi dataset General dan PUU
- Skenario pengujian berdasarkan hyperparameter tuning model
Pembahasan
Telah dilakukan pengujian model dengan berbagai skenario variasi pendekatan yang diimplementasikan. Berikut nilai dan hasil dari pengujian tersebut
Hasil Uji Coba Skenario Penggunaan Cosine Similarity
| Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|
| Tanpa Cosine Similarity | 71,29 | 73,22 | 66,67 | 69,79 |
| Dengan Cosine Similarity | 77,48 | 90,44 | 61,19 | 73,00 |
Dilakukan pengujian berdasarkan skenario penggunaan perhitungan cosine similarity dalam seleksi data pasangan ayat sebelum masuk ke dalam model. Tujuan skenario ini adalah untuk melihat pengaruh cosine similarity pada data pasangan ayat yang memiliki kemiripan struktur semantik kalimat. Nilai threshold yang digunakan sebagai batas nilai similarity pasangan kalimat adalah 0,75 untuk setiap cluster topic. Model yang digunakan dalam tahap ini masih menggunakan model fine tune pertama, karena model fine tune kedua akan diujicobakan di skenario berikutnya. Berdasarkan Tabel di atas, nilai performa model dengan menggunakan cosine similarity lebih baik dibandingkan dengan tanpa penggunaan cosine similarity, yakni dengan akurasi sebesar 77,48%.
Hal ini dikarenakan nilai cosine similarity tinggi (lebih dari 0,75) mampu menyeleksi pasangan ayat yang memiliki kemiripan semantik struktur kalimat yang tinggi. Sedangkan, data pasangan ayat dengan nilai similarity rendah dapat langsung dianggap selaras karena struktur semantik kalimatnya yang terlalu berbeda sehingga bisa dikatakan memiliki konteks pembahasan yang berbeda pula. Dengan dihilangkannya data pasangan tersebut, dapat mencegah noise yang masuk ke dalam model, sehingga bisa membantu model mengurangi kesalahan deteksi karena perbedaan konteks pasangan kalimat yang terlalu jauh.
Hasil Uji Coba Skenario Variasi Dataset
| Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|
| Dataset General | 77,48 | 90,44 | 61,19 | 73,00 |
| Dataset General + PUU | 93,07 | 98,87 | 87,06 | 92,59 |
Skenario selanjutnya adalah pengujian berdasarkan penggunaan variasi dataset dalam training model. Tujuan skenario pengujian ini adalah untuk mengetahui pengaruh penambahan dataset PUU terhadap performa model. Variasi model yang digunakan yaitu penambahan dataset memakai dataset PUU hasil label manual dengan bantuan ChatGPT. Pendekatan dari model ini sudah mengimplementasikan cosine similarity sebelum data pasangan ayat dimasukan ke model. Berdasarkan Tabel di atas, nilai performa model dengan menggunakan variasi penambahan dataset PUU memberikan nilai metrik yang jauh lebih baik dibandingkan performa model tanpa dataset PUU.
Hal ini dapat dijelaskan karena penggunaan dataset PUU tambahan memberikan model tambahan training data yang memiliki karakteristik struktur kalimat yang mirip dengan kalimat ayat yang ada di dokumen PUU. Model tersebut dapat mengambil relasi semantik antar kata dalam kalimat perundang-undangan secara lebih baik dibandingkan dengan model tanpa dataset PUU. Penggunaan variasi dataset PUU ini menjadi hal yang penting dilakukan karena membuat model menjadi lebih robust terhadap permasalahan yang dihadapi dalam penelitian ini, yakni ayat PUU.
Hasil Uji Coba Skenario Hyperparameter Tuning Model
| Learning Rates | Batch Size | Accuracy | Precision (%) | Recall (%) | F1-Score |
|---|---|---|---|---|---|
| 1e-5 | 6 | 92,33 | 98,30 | 86,07 | 91,78 |
| 1e-5 | 8 | 92,57 | 98,86 | 86,07 | 92,02 |
| 2e-5 | 6 | 92,33 | 97,75 | 86,57 | 91,82 |
| 2e-5 | 8 | 93,07 | 99,43 | 86,57 | 92,55 |
| 5e-5 | 6 | 93,07 | 100,00 | 86,07 | 92,51 |
| 5e-5 | 8 | 91,83 | 97,19 | 86,07 | 91,29 |
Skenario pengujian terakhir adalah pengujian terhadap hyperparameter tuning untuk menemukan parameter model yang menghasilkan performa model tertinggi. Nilai parameter yang digunakan untuk pengecekan kombinasi yaitu learning rates senilai 1e-5, 2e-5, 5e-5 dan batch size senilai 4, 6, 8. Pemilihan nilai kombinasi hyperparameter tersebut dipilih berdasarkan pengujian model pada sampel kecil dataset (model fine tune pertama). Berdasarkan Tabel di atas, nilai hyperparameter paling optimal adalah learning rates sebesar 2e-5 dan batch size sebesar 8.
Hasil ini dikarenakan jumlah dataset PUU yang masih sedikit sehingga didapatkan nilai batch size kecil lebih tepat digunakan untuk mendapatkan konteks data. Lalu, penggunaan nilai learning rates yang kecil akan menghasilkan performa yang lebih baik karena model sebelumnya telah dilakukan fine tune sehingga nilai weight sudah cukup mendekati optimalnya. Dengan menggunakan learning rates yang kecil, informasi yang diperoleh pada tahap training akan semakin detail, sehingga posisi weight lebih stabil dibandingkan model dari tahap fine tune sebelumnya.
Hasil Prediksi ke Semua Dokumen
Berdasarkan seluruh skenario uji coba yang telah dilakukan, digunakan model dengan performa terbaik, yakni model mDeBERTa dengan menggunakan tambahan dataset PUU, cosine similarity, learning rate 2e-5, dan batch size 8 untuk melakukan prediksi ke dataset keseluruhan 110 dokumen PUU. Dataset ini sebelum digunakan oleh model, telah melalui tahapan-tahapan yang telah dijelaskan di bagian metodologi. Proses tersebut menghasilkan dataset pasangan ayat perundang-undangan yang kalimatnya telah di-preprocess, di-cluster berdasarkan topic modeling, dan diseleksi menggunakan cosine similarity dengan nilai threshold 0,75. Selanjutnya data pasangan ayat tersebut dilakukan prediksi ketidakselarasan pada hubungan antar pasangan ayat tersebut. Gambar di bawah menunjukkan persebaran pasangan ayat tidak selaras yang terdeteksi berdasarkan topik.

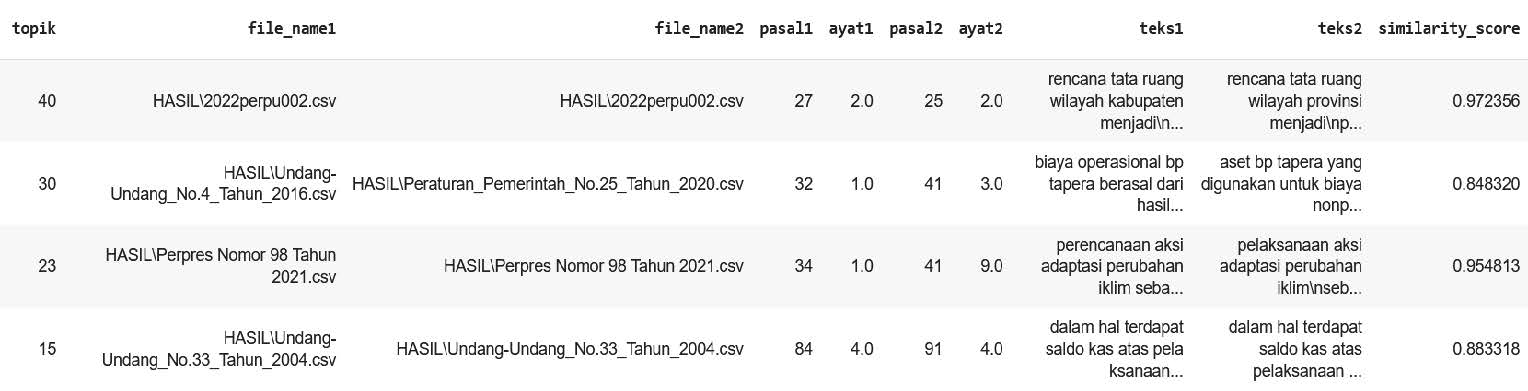
Hasil prediksi model, juga menyimpan informasi terkait pasangan ayat yang dideteksi tidak selaras. Contoh dari data tabel yang didapatkan dari model, mengenai data pasangan ayat yang terdeteksi tidak selaras dapat dilihat pada Gambar di bawah. Perbandingan pasangan kalimat ayat tersebut dapat dilihat pada di bawah.
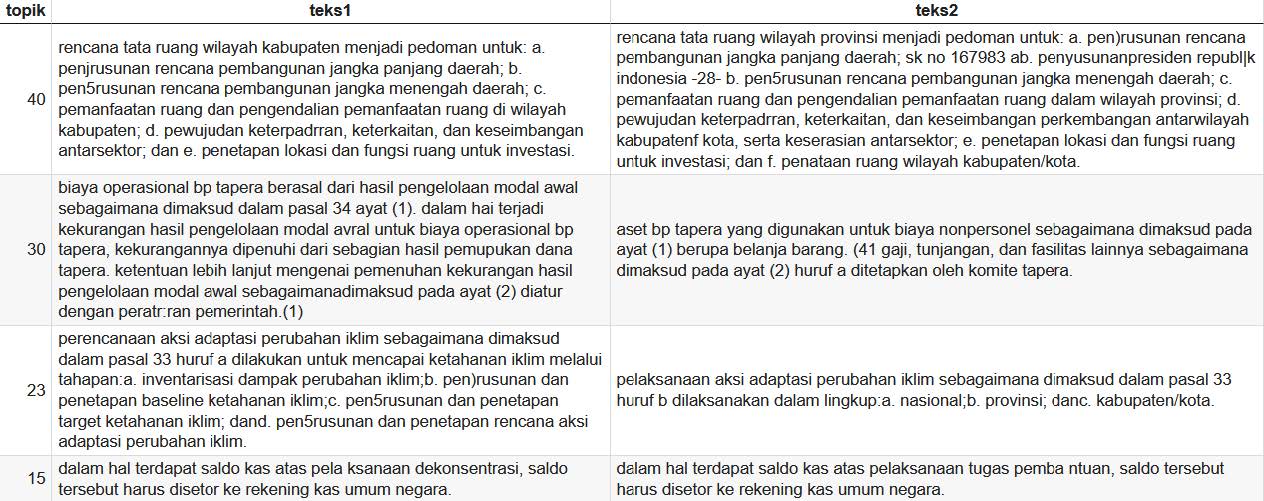
Penjelasan Hasil Prediksi
Berdasarkan Gambar di atas persebaran data pasangan ayat terdeteksi tidak selaras, didapatkan beberapa cluster yang memiliki jumlah data tidak selaras yang jauh lebih tinggi dibandingkan dengan lainnya. Hal ini disebabkan karena jumlah dokumen yang banyak di dalam cluster tersebut sehingga menyebabkan kombinasi pasangan ayat yang jauh lebih banyak serta probabilitas terdeteksinya ketidakselarasan yang lebih tinggi pula.
Gambar di atas merupakan contoh data pasangan ayat yang terdeteksi tidak selaras. Dapat dilihat bahwa pasangan ayat tersebut memiliki kemiripan struktur kalimat. Namun, terdapat perbedaan pada relasi semantik antar ayat dimana ditunjukkan dengan adanya perbedaan di beberapa kata. Perbedaan beberapa kata tersebut umumnya terjadi pada subjek kalimat, objek kalimat, dan kata negasi. Perbedaan tersebutlah yang ditangkap model untuk mendeteksi ketidakselarasan antar pasangan ayat.
Kesimpulan
Penelitian ini dilakukan untuk mendeteksi ketidakselarasan Peraturan Perundang-undangan Republik Indonesia menggunakan metode BERTopic dan mDeBERTa. Data yang digunakan dalam penelitian ini berupa 110 data dokumen (pdf dan docx) peraturan perundang-undangan negara mengenai investasi dengan jenis, tahun, dan tingkatan yang beragam. Data diekstraksi kemudian dilakukan preprocessing dengan melakukan lower case, remove links, spell checker, stemming, dan remove stopwords. Selanjutnya dilakukan topic modelling dan cosine similarity untuk menghasilkan kombinasi antar ayat dengan tingkat similaritas yang tinggi, yaitu dengan threshold 0,75 (nilai cosine similarity).
Dari hasil pengujian model dengan skenario pengujian penggunaan cosine similarity, didapatkan bahwa dengan menggunakan cosine similarity (untuk menyeleksi dataset) sebelum masuk ke model, dapat membantu performa model dalam mendeteksi ketidakselarasan data antar ayat. Penggunaan dataset PUU untuk fine tune model juga terbukti dapat membantu model untuk lebih memahami relasi semantik dalam data ayat perundang-undangan sehingga performa model menjadi meningkat dengan nilai accuracy sebesar 93,07%. Dilakukan juga hyperparameter tuning terhadap model untuk mendapatkan kombinasi hyperparameter terbaik. Kombinasi hyperparameter dengan nilai batch size sebesar 8 dan learning rates sebesar 2e-5 didapati memberikan model dengan hasil performa yang terbaik, dengan nilai matriks accuracy, precision, recall, dan f1-score secara berturut-turut, sebesar 93,07%, 99,43%, 86,57%, dan 92,55%.
Saran
Untuk penelitian selanjutnya, dapat dilakukan percobaan terhadap skenario pengujian nilai hyperparameter threshold cosine similarity. Selain itu, pemakaian dataset yang lebih banyak dapat membantu performa model dalam prediksi ketidakselarasan dalam peraturan perundang-undangan. Penggunaan POS tagging dapat dieksplorasi lebih lanjut untuk menentukan subjek dan objek kalimat agar dapat menangkap relasi antar ayat PUU.
Referensi
[1] Bayu, D. (2022, August 18). Hari Konstitusi, Berapa Jumlah Peraturan di Indonesia? DataIndonesia.id. Retrieved August 1, 2023, from Hari Konstitusi, Berapa Jumlah Peraturan di Indonesia? dataindonesia.id.
[2] Mahendra, A. O. (2010, March 29). Artikel Hukum Tata Negara dan Peraturan Perundang-undangan. Ditjenpp.Kemenkumham.go.id. Retrieved August 1, 2023, from https://ditjenpp.kemenkumham.go.id/index.php?option=com_content&view=article&id=421:harmonisasi-peraturan-perundang-undangan&catid=100&Itemid=180&lang=en.
[3] Susetio, W. (2013). DISHARMONI PERATURAN PERUNDANG-UNDANGAN DI BIDANG AGRARIA. Disharmoni Peraturan Perundang-Undangan di Bidang Agraria, 1-14. https://media.neliti.com/media/publications/18020-ID-disharmoni-peraturan-perundang-undangan-di-bidang-agraria.pdf
[4] Wahyuni, W. (2023, February 7). 2 Lembaga yang Berwenang Menguji Peraturan Perundang-undangan. Hukumonline.com. Retrieved August 1, 2023, from https://www.hukumonline.com/berita/a/2-lembaga-yang-berwenang-menguji-peraturan-perundang-undangan-lt63e20c084d65a/
[5] Florence Sedes, M. M. J. K. (2018). Using K-Means for Redundancy and Inconsistency Detection: Applivation to Industrial Requirements. Article, 1. https://doi.org/10.1007/978-3-319-91947-8_52
[6] Huang, X. (2021). Detecting inconsistencies of safety artifacts with Natural Language Processing. Article. https://gupea.ub.gu.se/bitstream/handle/2077/74542/thesis_XuniHuang.pdf?sequence=1
[7] Fahrurrozi Rahman, R. M. A. F. S. L. A., Clara Vania (2021). IndoNLI: A Natural Language Inference Dataset for Indonesian. Article. https://doi.org/
[8] Nafide Sadat Moosavi, P. A. U. J. B., Iryana Gurevych (2022). Falsesum: Generating Document-level NLI Examples for Recognizing Factual Inconsistency in Summarization. Article. https://doi.org/
[9] Budianto, V. A. (2022, April 26). 3 Asas Hukum: Lex Superior, Lex Specialis, dan Lex Posterior Beserta Contohnya. Https://www.Hukumonline.com/. Retrieved August 1, 2023, from https://www.hukumonline.com/klinik/a/3-asas-hukum--ilex-superior-i--ilex-specialis-i--dan-ilex-posterior-i-beserta-contohnya-cl6806/
[10] Weizhu Chen, P. H. J. H. (2023). DEBERTAV3: IMPROVING DEBERTA USING ELECTRA-STYLE PRE-TRAINING WITH GRADIENTDISENTANGLED EMBEDDING SHARING. Article. https://doi.org/