- Published
Mendeteksi Kondisi Kesehatan Mental Pengguna Twitter menggunakan NLP
- Published
- Labib Alfaraby, Gaudhiwaa Hendrasto, dan Surya Abdillah
Media sosial merupakan media bagi orang-orang untuk mencurahkan apa yang sedang dirasakan, dilakukan, dan dihadapi. Pada penelitian ini, dilakukan percobaan untuk melakukan klasifikasi teks untuk memprediksi ada atau tidak pengguna media sosial itu mengalami stres dengan menggunakan tweet dan komentar yang mereka unggah. Tahapan dalam penelitian ini adalah pengumpulan data, praproses data, pseudo labeling, ekstraksi topik, dan kategorisasi data berdasarkan topik. Dataset yang berisikan unggahan pengguna Twitter digunakan dalam pengembangan model Bidirectional Encoder Representations (IndoBERT) untuk klasifikasi stres. Pengembangan model LSTM dan BiLSTM juga dilakukan sebagai pembanding terhadap akurasi IndoBERT. Didapatkan model terbaik adalah IndoBERT dengan nilai akurasi 66%. Setelah itu, dikembangkan model untuk melakukan topic modeling terhadap unggahan pengguna sehingga diperoleh topik permasalahan apa yang sedang dialami oleh pengguna tersebut dengan menggunakan BERTopic. Hasil koherensi dari topic modeling adalah 62%. Penelitian ini diharapkan dapat berguna sebagai salah satu metode untuk mendeteksi stres pengguna media sosial dari tweet yang mereka lontarkan. Melalui kategorisasi kondisi kesehatan mental yang dilakukan pada model tweet ini, hasilnya dapat dijadikan acuan bagi berbagai layanan masyarakat yang berhubungan dengan kesehatan mental, seperti hotline kesehatan mental, layanan konseling, dan kampanye terhadap kesadaran kesehatan mental.
Kata Kunci: Media Sosial, Stres, Kesehatan Mental, Topic Modeling, BERTopic
Latar Belakang
Pada era digitalisasi ini, ketergantungan manusia terhadap teknologi sangatlah erat, terutama pada penggunaan telepon genggam atau smartphone. Smartphone sudah menjadi lifestyle atau gaya hidup sekarang ini yang mana mulai dari bangun tidur hingga akan tertidur aktivitas yang kita lakukan seakanakan sudah terhubung dengan smartphone. Sebagai contoh, ketika akan pergi ke kantor, kita akan melihat jam melalui smartphone, lalu pada saat akan bertemu dengan teman, kita juga akan berkomunikasi terlebih dahulu melalui smartphone yang kita miliki untuk menentukan tempat dan waktu bertemu, dan tentu banyak contoh lainnya.
Media sosial merupakan aplikasi yang wajib terinstall di dalam smartphone pengguna dewasa ini, semua orang yang menggunakan smartphone pasti mempunyai minimal satu akun media sosial yang terdaftar. Media sosial memungkinkan keterhubungan antara satu pengguna (dikenal dengan follower dan following) dengan pengguna lain sehingga interaksi secara virtual sangat memungkinkan untuk terjadi. Dalam media sosial, kebanyakan pengguna akan mencurahkan kegiatan-kegiatan yang mereka lalui dalam hari itu, bisa dalam bentuk dokumentasi foto atau curahan kata-kata. Reaksi yang mereka tunjukkan tentunya beragam, momen senang dan bahagia atau dapat berupa perasaan sedih dan cemas. Oleh karena itu, media sosial ini dapat menjadi wadah bagi setiap orang untuk mencurahkan dan menunjukkan perasaan atau isi hati pengguna. Adapun, faktor yang paling mempengaruhi dalam penyebaran informasi pada media sosial merupakan faktor pribadi, yakni kemampuan dan motivasi, serta faktor lingkungan, yakni kekuatan ikatan pada jejaring media sosial (Hapsari, Nurul Fiktirati Ayu, 2020).
Stres merupakan salah satu kondisi yang sering digambarkan pada unggahan media sosial. Stres sendiri merupakan gangguan atau kekacauan mental dan emosional yang disebabkan oleh faktor luar. Studi American Psychological Association (APA, 2012) telah menunjukkan bahwa generasi milenial (umur 18 hingga 33) memiliki rata-rata nilai stres level paling tinggi, yakni 5,4 dan diperburuk dengan tidak adanya kemampuan dalam mengatur stres itu sendiri. Generasi pada umur 18 hingga 33 di Indonesia dapat digolongkan sebagai masa dewasa awal dimana seseorang akan menghadapi berbagai masalah emosi dalam kehidupannya. Di sisi lain kondisi stres ini, bagaimanapun juga kategori dewasa awal ini memiliki tanggung jawab yang besar sebagai agent of change dan memegang pengaruh besar terhadap perkembangan dan kemajuan bangsa. Oleh sebab itu, diperlukan sebuah upaya penanganan stres sesegera mungkin demi perkembangan dan kemajuan bangsa Indonesia.
Tujuan
Berdasarkan latar belakang di atas, tujuan penelitian prediksi kondisi stress pengguna media sosial adalah sebagai berikut:
Mengetahui kondisi stres pengguna sosial media
Membangun model Natural Language Processing (NLP) untuk memprediksi kondisi stres pengguna pada unggahan media sosial
Manfaat
Hasil penelitian ini diharapkan dapat membawa manfaat terhadap peneliti, pembaca, masyarakat, dan pemerintah sebagaimana dijelaskan berikut:
a. Peneliti
Penelitian ini menjadi salah satu cara bagi peneliti untuk menggali ilmu pengetahuan baru dan menambah semangat bagi penelitian untuk berkarya.
b. Pembaca
Penelitian ini dapat menjadi dasar dan inspirasi bagi peneliti lain untuk mengembangkan penelitian lanjutan.
c. Masyarakat
- Hasil dari Penelitian ini dapat digunakan sebagai salah satu metode untuk mendeteksi stres dari tweet yang dilontarkan.
- Hasil dari penelitian ini dapat memberikan pemahaman lebih baik mengenai kondisi stres pengguna media sosial
Batasan Masalah
Berikut batasan dan masalah pada penelitian ini adalah sebagai berikut:
Data yang diambil terbatas pada media sosial Twitter. Pengumpulan data dilakukan dengan melakukan pengumpulan data pada Twitter menggunakan kata kunci terkait stres.
Fokus analisis terbatas pada unggahan teks berbahasa Indonesia dalam media sosial yang menunjukkan kondisi stres pengguna. Analisis tidak melibatkan elemen visual seperti gambar atau video.
Metodologi
Berdasarkan peninjauan pustaka yang telah dilakukan, maka untuk mencapai tujuan dari penelitian ini disusunlah rangkaian proses penelitian pada Gambar 6.

Pengumpulan Data
Pengumpulan data dilakukan dengan pencarian pada media sosial Twitter dengan menggunakan pustaka snscrape. Tujuan pengumpulan data ini adalah untuk mendapatkan tweet pengguna dengan kondisi stres. Adapun kata kunci yang digunakan dalam pengumpulan data, yaitu: capek, cemas, cutting tangan, trauma, belum lolos, capek skripsi, pacaran galau, kurang tidur. Total data yang terkumpul adalah 1823 baris data. Data-data ini terdiri dari kolom link dan kolom tweet.
Preprocessing
Setelah data terkumpul, maka dilakukan preprocessing untuk dapat mengoptimalkan pembuatan model. Preprocessing yang dilakukan, yaitu: a. case folding: perubahan teks menjadi huruf kecil b. penghapusan bagian yang tidak digunakan: bagian yang dihapuskan adalah emoji, hashtag, mention dan tautan pada cuitan c. penanganan kata alay: dilakukan perubahan kata-kata alay menjadi kata formal dengan menggunakan kamus alay d. stemming: merupakan proses perubahan kata menjadi kata bentuk dasar e. perubahan stopwords: menghilangkan kata-kata yang memiliki makna yang tidak terlalu penting f. slang remover: pengubahan atau penghapusan kata-kata gaul g. filter data: dilakukan penghapusan kata dengan jumlah huruf kurang dari 3 dan menghapus data dengan jumlah kata kurang dari 5
Topic Labeling
Dilakukan langkah topic labeling untuk mendapatkan tweet yang termasuk ke dalam kategori stress. Dilakukan beberapa langkah dalam proses ini, yaitu:
- pemberian label stres secara manual pada sebagian data hasil preprocessing
- pembuatan model prediksi dengan metode LSTM, BiLSTM, dan IndoBERT pada data terlabel
- prediksi label stres dengan model LSTM, BiLSTM, dan IndoBERT yang telah dibuat
- Evaluasi model
Topic Modelling
Data hasil prediksi model dengan nilai evaluasi terbaik pada langkah pseudo labelling akan digunakan dalam proses ekstraksi topik. Adapun, metode yang digunakan adalah BERTopic dengan menggunakan 5 langkah utama, yakni embed documents, dimensionality reduction, cluster documents, bag-of-words, dan topic representation. Setelah didapatkan topik dari model BERTopic, akan dilakukan evaluasi dengan menggunakan nilai koherensi. Daftar kata dalam topik dengan nilai koherensi terbaik akan digunakan sebagai acuan dalam penentuan kategori stres. dan kemudian digunakan sebagai model untuk mengkategorisasikan setiap dokumen dengan topic yang bersesuaian.
Hasil Pembahasan
Dalam penelitian ini, telah dikumpulkan 2000 data dari Twitter. Data diambil dengan menggunakan kata kunci khusus untuk mendapatkan cuitan yang relevan dengan kondisi kesehatan mental pengguna. Setelah melewati pra-pemrosesan, didapatkan 1823 data yang siap untuk diolah lebih lanjut. Untuk mengolah tweet-tweet tersebut, dilakukan beberapa tahapan, yaitu menghapus data duplikasi, case folding, pembersihan teks, penghapusan kata-kata umum (stopword removal), tautan, dan stemming. Contoh hasil sebelum dan sesudah pra-pemrosesan dapat dilihat pada tabel 2.
| No. | Tautan Cuitan | Teks Sebelum Pra-pemrosesan | Teks Setelah Pra-pemrosesan |
|---|---|---|---|
| 1 | https://twitter.com/jji ... | W udah gapapa siapa aja yg sanggup nemenin hanbin live ultah nanti (live sebentar pun w gamasalah) gegera ngeliat semalem mereka nyampe airport se chaos itu sksksks. Trauma dikit2 pasti ada apalagi maknaes. Orgil semua tu fans2 egois yg di airport. | aku gapapa sanggup nemenin hanbin live ultah live sebentar aku gamasalah gegera lihat semalem airport chaos sksksks trauma dikit maknaes orgil fan egois airport |
| 2 | https://twitter.com/ser ... | Gue stress 😭😭😭 udah H-2 deadline malah masi kurang banyak wkwk | aku stres deadline ketawa |
Dalam proses labelling, kami melakukan penandaan secara manual terhadap 1556 data. Kolom "stres" digunakan untuk menyimpan nilai label, yang dapat berupa 1 atau 0. Nilai 1 menunjukkan bahwa tweet tersebut berasal dari pengguna yang mengalami stres, sedangkan nilai 0 menunjukkan bahwa tweet tersebut berasal dari pengguna yang tidak mengalami stres.
Selanjutnya dilakukan pseudo labelling pada data yang tersisa. Pseudo labelling dilakukan dengan menggunakan teknik LSTM (Long Short-Term Memory), BiLSTM (Bidirectional LSTM), dan BERT (Bidirectional Encoder Representations from Transformers). Ketiga teknik tersebut digunakan untuk mendapatkan akurasi terbaik dalam memprediksi kondisi pengguna dalam keadaan stres ataupun tidak, serta menambahkan data 1 atau 0 dalam kolom “stres”. Didapatkan nilai akurasi model LSTM, BiLSTM, dan IndoBERT secara berurutan adalah 0.644, 0.613, dan 0.681.
Data prediksi model IndoBERT akan disatukan dengan data yang telah dilabeli secara manual. Dari data tersebut, akan digunakan data terlabel stres untuk mendapatkan kategori stres dengan menggunakan BERTopic. Adapun persebaran kata dalam label stres dapat dilihat pada Gambar 7.

Dalam topic labeling menggunakan BERTopic dilakukan pengujian nilai parameter, dan diapatkan hasil pada Tabel 2. Parameter nr_topics merujuk pada jumlah topik yang diinginkan dalam model. Dalam salah satu kasus, jumlah topik yang digunakan adalah 3, yang berarti model akan mencoba untuk mengidentifikasi 3 topik yang berbeda dalam dataset. Parameter min_topic_size adalah ukuran minimum topik yang diizinkan. Artinya, topik dengan ukuran kurang dari min_topic_size akan diabaikan. Dalam salah satu kasus, ukuran minimum topik yang diizinkan adalah 10, sehingga jika ada topik yang kurang dari 10 dokumen yang relevan, topik tersebut tidak akan diperhitungkan. Hasil koherensi adalah metrik yang digunakan untuk mengukur kualitas interpretabilitas (mengartikan dan memahami) topik dalam model. Nilai koherensi berkisar antara 0 hingga 1, di mana nilai yang lebih tinggi menunjukkan tingkat koherensi yang lebih baik.
| nr_topics | min_topic_size | koherensi |
|---|---|---|
| 3 | 10 | 0.3648 |
| 3 | 15 | 0.3670 |
| 3 | 20 | 0.3648 |
| nr_topics | min_topic_size | koherensi |
|---|---|---|
| 4 | 10 | 0.6129 |
| 4 | 15 | 0.6190 |
| 4 | 20 | 0.5067 |
| nr_topics | min_topic_size | koherensi |
|---|---|---|
| 5 | 10 | 0.6129 |
| 5 | 15 | 0.5680 |
| 5 | 20 | 0.6194 |
Dari beberapa parameter tersebut, digunakan nr_topics 5, min_topic_size 20, dan nilai koherensi 0.6194. Meski parameter nr_topics, yakni jumlah topik yang diekstrak diatur 5, didapatkan satu topik dengan nilai -1, yang berarti topik ini tidak memiliki makna yang kuat, sehingga topik dengan nilai -1 tidak akan digunakan. Hasil dari proses topic modeling ini adalah beberapa kategori topik pada Gambar 8. Kategori topik terbagi menjadi empat, yaitu topik 0 sampai topik 3 secara berturut-turut dilabeli dengan topik: trauma, menyakiti diri, beban kerja, dan hubungan.
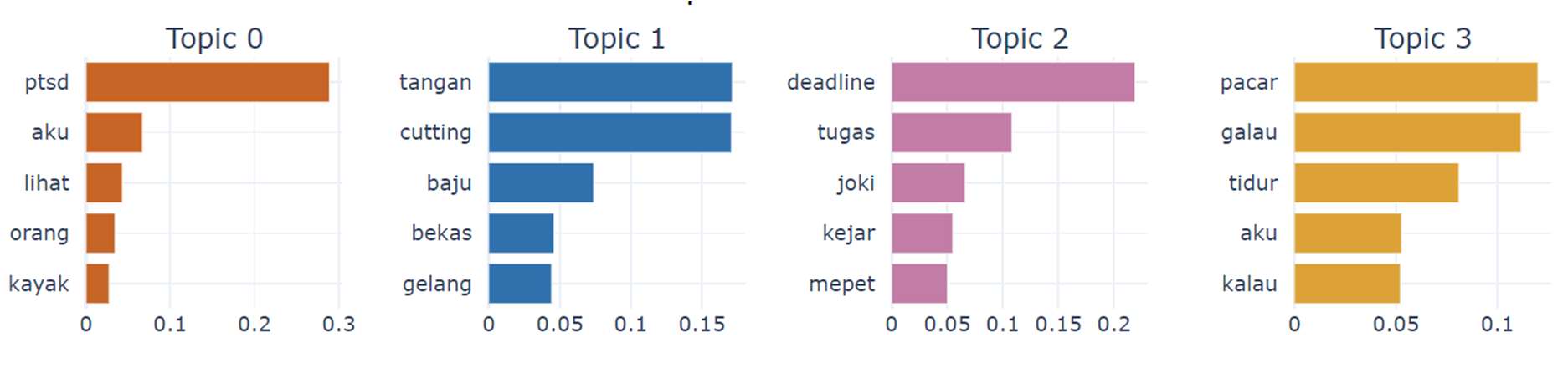
Dengan menggunakan empat kategori tersebut, dilakukan pelabelan kategori stres menggunakan BERTopic terhadap data tweet. Hasil dari pelabelan bisa dilihat pada Tabel 4.
| No. | Tweet Topik | Topik |
|---|---|---|
| 1 | Tapi akhir akhir ini bella kayaknya banyak sedih. Snap nya galau muluu, dan postingin foto orang tuanya. Kayaknya dia lagi banyak fikiran. Aku ga berani buka obrolan kalau ga dia yang ngajak ngbrol. Karena gimanapun dia udah nikah bukan pacaran lagi | hubungan |
| 2 | Gue stress 😭😭😭 udah H-2 deadline malah masi kurang banyak wkwk beban Kerja | beban kerja |
| 3 | Tapi kadang suka malu soalnya ada bekas cutting di tangan jd ke notice bgt wkwk menyakiti diri | menyakiti diri |
| 4 | @lazsitude the last image itu bikin aku ptsd. trauma | trauma |
Kesimpulan
Penelitian ini memperkenalkan sebuah metode untuk menganalisis sentimen kontekstual dari tweet yang berasal dari masyarakat terkait kondisi kesehatan mental pengguna di Indonesia. Data yang digunakan dalam penelitian ini diperoleh dari Twitter yang difokuskan untuk mendapatkan kondisi kesehatan mental. Pada proses pseudo labelling didapatkan akurasi untuk model LSTM, BiLSTM, dan IndoBERT secara berurutan adalah 0.644, 0.613, dan 0.681. Sehingga, dapat ditarik kesimpulan bahwa model IndoBERT merupakan model terbaik dalam proses memprediksi kondisi stres atau tidaknya pengguna karena memiliki akurasi tertinggi, yakni 68%. Nilai akurasi ini dapat dikatakan rendah, tetapi dengan menimbang jumlah data yang sedikit model ini bisa dikatakan sudah cukup baik. Dengan menggunakan metode yang diajukan, yakni BERTopic kategori dalam tweet dapat dikategorikan menjadi trauma, menyakiti diri, beban kerja, dan hubungan, yang mencerminkan kondisi kesehatan mental pengguna. Selain itu, metode yang diusulkan juga mampu mengenali ketiga jenis tanggapan tersebut dengan tingkat koherensi 66%. Adapun tingkat akurasi dan koherensi terhitung rendah diakibatkan karena kurangnya dataset, yakni 1823 data.
Melalui kategorisasi kondisi kesehatan mental yang dilakukan pada model tweet ini, hasilnya dapat dijadikan acuan bagi berbagai layanan masyarakat yang berhubungan dengan kesehatan mental. Misalnya, hasil kategorisasi ini dapat digunakan sebagai panduan dalam menyediakan hotline kesehatan mental yang dapat diakses oleh masyarakat untuk mendapatkan bantuan dan dukungan. Selain itu, informasi yang terkandung dalam tweet juga dapat membantu penyedia layanan konseling untuk lebih memahami kebutuhan dan permasalahan yang dihadapi oleh masyarakat. Dengan memanfaatkan hasil kategorisasi ini, kampanye terhadap kesadaran kesehatan mental juga dapat dirancang dengan lebih efektif dan tepat sasaran, sehingga dapat meningkatkan pemahaman dan dukungan masyarakat terhadap isu-isu kesehatan mental.
Daftar Pustaka
A. Kene and S. Thakare, "Mental Stress Level Prediction and Classification based on Machine Learning," 2021 Smart Technologies, Communication and Robotics (STCR), Sathyamangalam, India, 2021, pp. 1-7, doi: 10.1109/STCR51658.2021.9588803.
Ayu , N. I. F., Hapsari, Saleh, A., & Ardyawin, I. (2020). INFORMATION SHARING BEHAVIOUR DI MEDIA SOSIAL. Universitas Muhammadiyah Mataram, Vol 2, No 2 (2020): November. https://doi.org/10.31764/jiper.v2i2.3456
Baranwal, S. (2016, 7 Juli). Understanding BERT. Medium. Diakses 2 Juli 2023, dari https://pub.towardsai.net/understanding-bert-b69ce7ad03c1
Baranwal, S. (2020, 17 Februari). Understanding BERT. Medium. Diakses 2 Juli 2023, dari https://pub.towardsai.net/understanding-bert-b69ce7ad03c1
Geeksforgeeks (2023, 23 Maret). What is Web Scraping and How to Use It? Diakses 2 Juli 2023, dari https://www.geeksforgeeks.org/what-is-web-scraping-and-how-to-use-it/
Grootendorst, M. (2020, 5 Oktober). Topic Modelling with BERT. Medium. https://towardsdatascience.com/topic-modeling-with-bert-779f7db187e6
Horev, Rani. (2018, 11 November). BERT Explained: State of the art language model for NLP. Diakses 12 Juli 2023, dari https://towardsdatascience.com/bert-explainedstate- of-the-art-language-model-for-nlp-f8b21a9b6270
JustAnotherArchivist. (2020). snscrape. Diakses 2 Juli 2023, dari https://github.com/JustAnotherArchivist/snscrape
Katryn, R. G. (2023, 23 Maret). Text Preprocessing: Tahap Awal dalam Natural Language Processing (NLP). Diakses 2 Juli, 2023, dari https://medium.com/mandiriengineering/ text-preprocessing-tahap-awal-dalam-natural-language-processing-nlpbc5fbb6606a
Maarten. (2020). BERTopic. Diakses 2 Juli 2023, dari https://maartengr.github.io/BERTopic/index.html
Manaswi, N. K. (2018). Deep Learning with Applications Using Python (1st ed.). Apress.
Nijhawan, Tanya & Attigeri, Girija & Thalengala, Ananthakrishna. (2022). Stress detection using natural language processing and machine learning over social interactions.
Journal of Big Data. 9. 10.1186/s40537-022-00575-6.
Prakruthi Manjunath, Twinkle S, Pola Shreya, Vismaya Ashok, Dr. Shabana Sultana, 2021,
Predictive Analysis of Student Stress Level using Machine Learning,
INTERNATIONAL JOURNAL OF ENGINEERING RESEARCH & TECHNOLOGY (IJERT) NCCDS – 2021 (Volume 09 – Issue 12),
Prijono, B. (2018). Jaringan LSTM terdiri dari modul LSTM yang dipanggil secara berulang [Photograph]. https://Indoml.com/2018/04/13/Pengenalan-Long-Short-Term-Memory-
Lstm-Dan-Gated-Recurrent-Unit-Gru-Rnn-Bagian-2/. https://indoml.files.wordpress.com/2018/04/lstm.jpg
Rijcken, Emil. (2023, 3 Januari). Cv Topic Coherence Explained. Diakses 12 Juli 2023, dari https://towardsdatascience.com/c%E1%B5%A5-topic-coherence-explainedfc70e2a85227
Shenoy, A. (2019, 3 Desember). Pseudo-Labeling to deal with small datasets — What, Why & How?. Diakses 12 Jul 2023, dari https://towardsdatascience.com/pseudo-labelingto- deal-with-small-datasets-what-why-how-fd6f903213af
Sheridan, S. (2022, 16 November). What Is Topic Modeling? A Beginner's Guide. Diakses 2 Juli 2023, dari https://levity.ai/blog/what-is-topic-modeling
Singh, R. (2021, 4 Oktober). Topic Labeling. Diakses 2 Juli 2023, dari https://medium.com/nerd-for-tech/topic-labeling-16f0a1335450
Trivusi (2022, 17 September). Mengenal Algoritma Long Short Term Memory (LSTM). Diakses 2 Juli 2023, dari https://www.trivusi.web.id/2022/07/algoritma-lstm.html
WHO (2023, 21 Februari). Stress. World Health Organization. Diakses 2 Juli 2023, dari https://www.who.int/news-room/questions-and-answers/item/stress
Yosia, M. (2023, 14 April). Beda Eustress dan Distress serta Cara Menghadapinya. Diakses 2 Juli, 2023, dari https://hellosehat.com/mental/stres/eustress-dan-distress/